

Disaster Recovery (DR): WHY and HOW
By Piyush Jalan / Mar 13,2023
Disaster Recovery (DR) in Cloud Computing involves the use of cloud solutions to ensure the continuity and reliability of business operations in the event of a disaster. It ensures that businesses can quickly recover their critical IT systems and data, minimizing disruption to their operations. By leveraging cloud resources, companies can create a comprehensive Disaster Recovery (DR) plan that is cost effective, scalable and flexible. Furthermore, with Disaster Recovery Cloud Computing, companies can benefit from low latency, improved performance and increased security.

WHY DR?
Since downtime might result in losses of millions of dollars or possibly the closure of the company as a whole, businesses are growing less tolerant of it. This is the main factor driving firms to increase their resource allocation in an effort to attain a high level of business continuity.
A disaster recovery plan guarantees that your business’s infrastructure, including its apps, will always be accessible, even in the event of a calamity. A disaster recovery plan may also boost your company’s credibility because you can ensure that your clients will continue to get services. You will have a competitive advantage as a result.
HOW to achieve DR?
When a disaster strikes, the emergency team’s initial focus should be on doing a rapid analysis of the situation to determine what hardware, software, data, or systems were damaged and, as a result, to determine which phase of the recovery plan should be carried out.
After the contingency is over, the plan’s implementation must be reviewed again to identify its weaknesses and strengths and implement the required modifications. The disaster recovery plan should be evaluated and revised on a regular basis, even if there is no catastrophe, to make it better. Keep in mind that risks and businesses change regularly, making any strategy obsolete if it is not updated frequently enough.
You must be aware of the time needed to restore data from your backup since every minute that an application is unavailable can negatively impact company, finances, and the reputation of an organization. Two terminologies that are frequently used in the sector for disaster planning are:
Recovery Point Objective (RPO): RPO is the time-based assessment of the tolerable level of data loss.
Recovery Time Objective (RTO): This term refers to the amount of time needed to recover a business process to its pre-disaster state.
NOTE: Organizations may plan cloud-based solutions to offer system recovery services that are both timely and cost-effective, depending on RPO, within the parameters set by RTO.
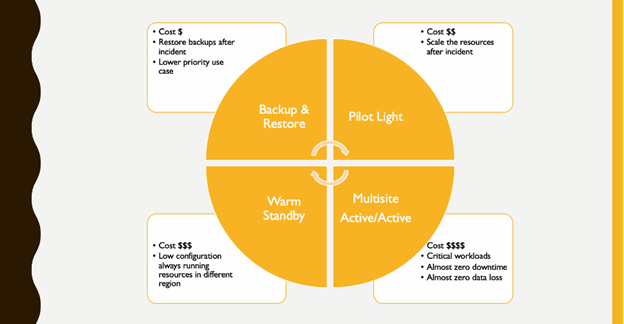
The disaster recovery options that AWS cloud provides may be generally divided into four categories, ranging from simple backup methods with little cost and complexity to more intricate plans utilizing many active Regions. An active site hosts the workload and serves traffic in active/passive schemes. For rehabilitation, the passive site is utilized. Until a failover event is initiated, the passive site is not actively serving traffic. Remember that the data plane and the control plane are how services are often split up within AWS when picking your approach and the AWS resources to achieve it. Real-time service delivery is the responsibility of the data plane, while environment configuration is done via control planes. Only data plane activities should be used as part of your failover operation for optimal resilience. The reason for this is, data aircraft frequently have greater availability design goals than control planes.
With advancements in technology, disaster recovery plans change. Physically moving tapes or copying data to a different location may be part of an on-site disaster recovery strategy. For your organization to achieve its DR goals on AWS, you must reassess the financial effect, risk, and cost of your firm’s prior disaster recovery methods.
Implementing a highly available workload in many Availability Zones inside a single AWS Region helps protect against natural and technological disasters for a disaster event based on disruption or loss of one physical data center. The danger of human hazards, such as an error or an illegal behavior that might lead to data loss, can be reduced by continuously backing up data inside this single Region. Each Availability Zone in an AWS Region is separate from faults in the other zones and is made up of a number of them. One or more distinct physical data centers make up each availability zone in turn. You can divide workloads among several zones in the same Region to better isolate problematic situations and achieve high availability.
Final thoughts
Customers are accountable for the accessibility of their cloud-based apps. It is crucial to identify a catastrophe and establish a disaster recovery plan that takes into account both this definition and the potential effects on business outcomes. Select the best architecture to mitigate against catastrophes after creating RTO and RPO based on impact analyses and risk assessments. Make sure catastrophe detection is feasible and quick; it’s critical to understand when goals are in danger. Be careful to create a plan and test it before implementing it. Unvalidated disaster recovery plans run the danger of not being implemented owing to lack of trust or failing to achieve disaster recovery goals.
Next steps
AWS Backups, CloudEndure, AWS DRS, Automated backup solutions etc. are few DR solution provided by AWS Cloud. I’ll be talking about deep technically for AWS DRS and CloudEndure in my next write-up.
Stay tuned!
Please feel free to write @ [email protected] for any queries on DR and BCP guide.
Thanks!
