

Improve your search encounters with AI-driven Amazon Kendra
By Bhuvaneswari Subramani / Mar 22, 2024
Table of Contents
- Introduction
- Amazon Kendra
- Clean-up
- Roles are different for index, data source and experience. Why & how?
- Resources
- Conclusion
Introduction
Technological advancements open doors to drive scientific exploration, accelerate human progress, and enhance quality of life. Artificial Intelligence (AI) tools stand out as particularly promising in this regard. Amazon Kendra and Amazon Q are two powerful tools that exemplify this potential. Amazon Kendra revolutionizes search experiences, offering natural language processing capabilities that enable users to discover information more intuitively and efficiently. It's particularly valuable for enterprises dealing with vast amounts of data, enhancing productivity and decision-making processes.
Amazon Kendra
When you wanted to find accurate information faster in situations like improving customer interactions and boost workforce productivity, an intelligent search is the way to go. Amazon Kendra is an intelligent search service powered by machine learning which uses natural language search capabilities to help your organization quickly return accurate answers from unstructured content.
Traditional Search vs Intelligent Search
Amazon Kendra, the intelligent search service, offers numerous advantages over traditional services, particularly when searching through unstructured data such as PDFs, Word documents, or HTML pages.
- Kendra's intelligent search capabilities enable it to understand natural language, providing more accurate answers to search queries instead of simply providing links to documents.
- Kendra continuously improves over time by fine-tuning its machine learning models on a periodic basis.
- Implementation is easy with the click of a button, allowing users to quickly find the answers they are looking for.
Kendra is pre-trained with 14 industry domains
Let’s explore Kendra deeper
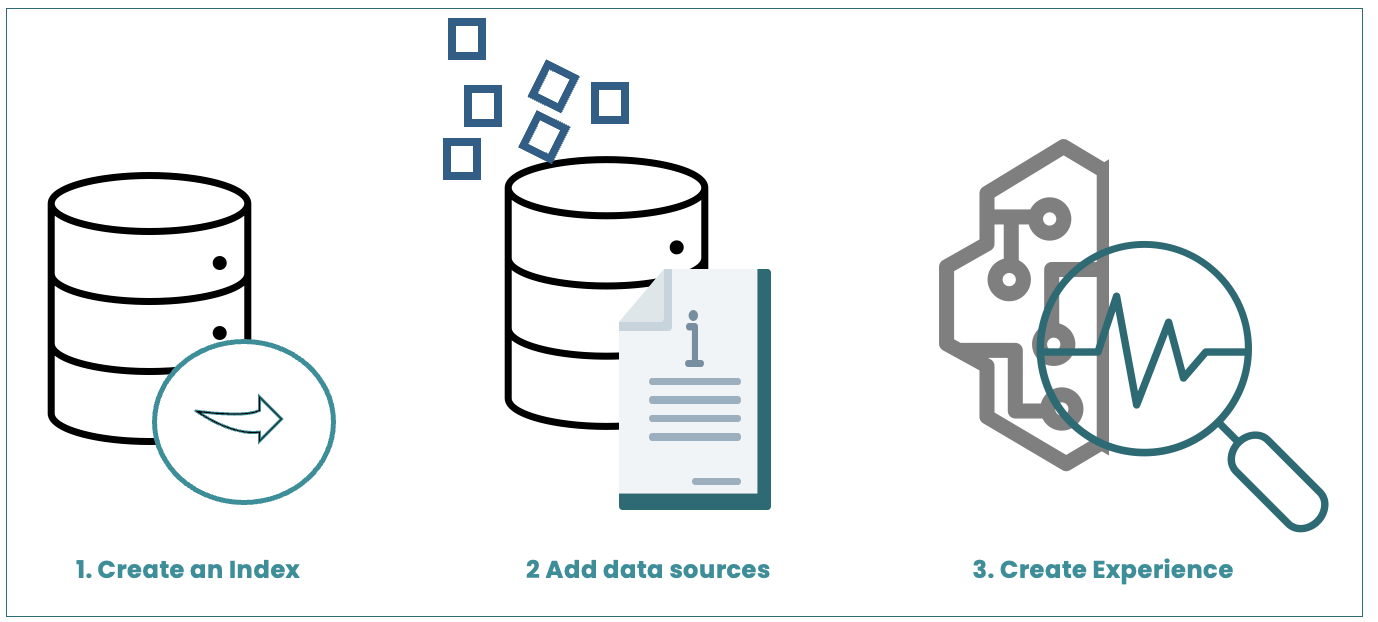
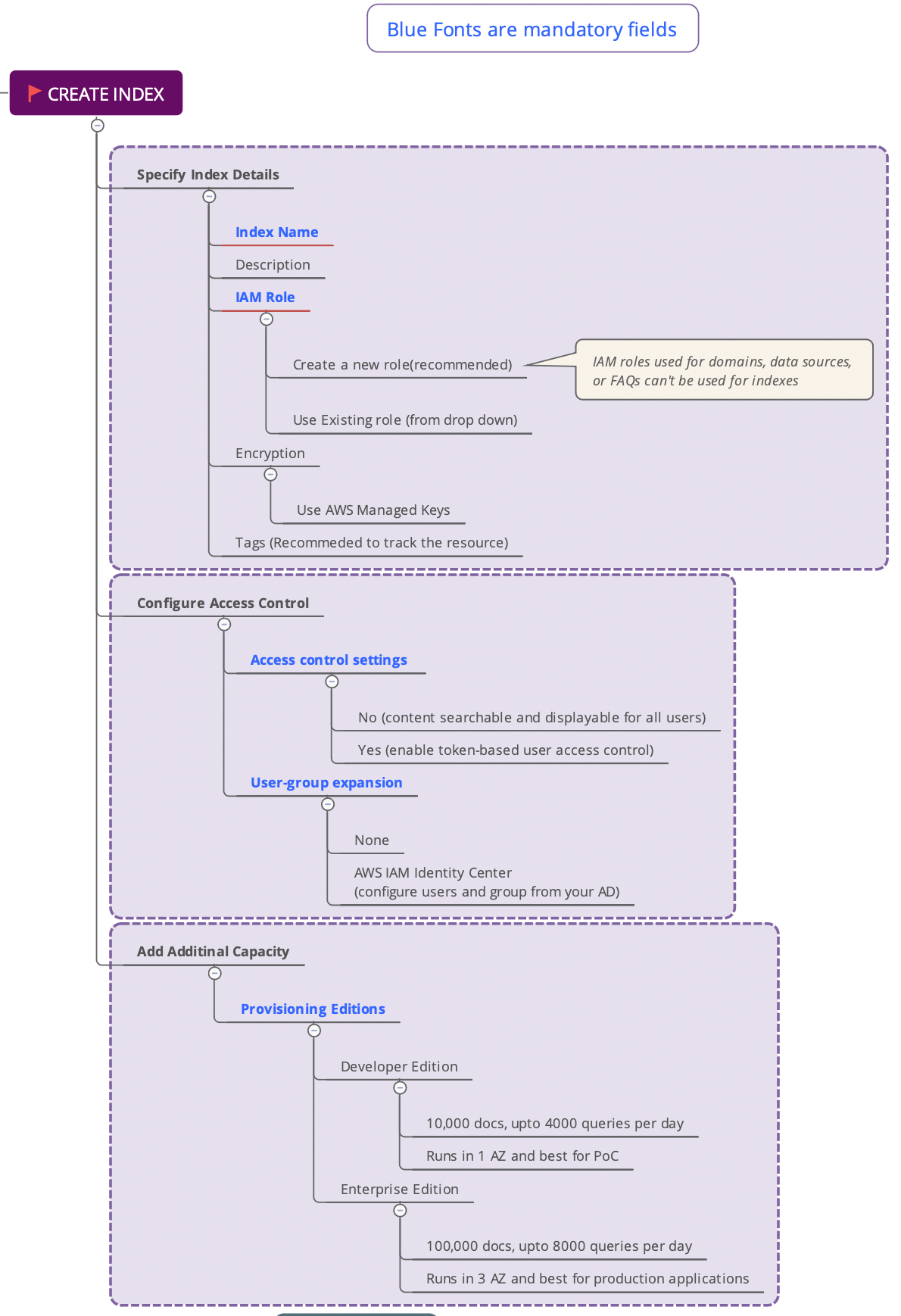
Create index
- Login into AWS Console
- Go to Amazon Kendra service
- Follow the instructions in the below image to create the index in Amazon Kendra
- Observe the Active status, note down the Role ARN and Index ID. This will help you to verify once you add to Amazon Q or Amazon Bedrock for integration.
Important Note:
As per the below process, you please create a new role for the index, data source and experience.
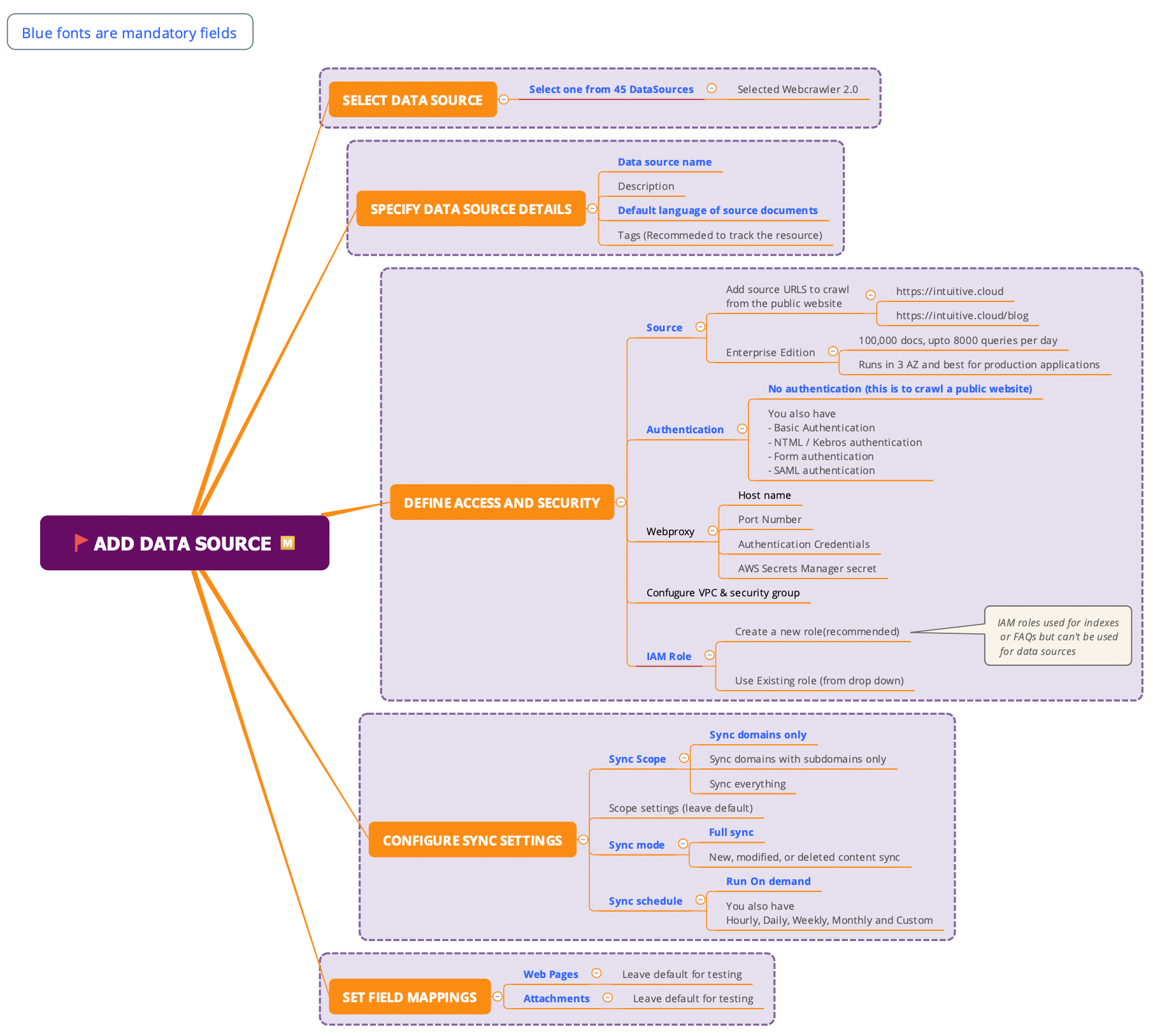
Add Data source
Amazon Kendra comes with data source connector to connect your documents and index data to an Amazon Kendra index. You can create a data source connector for Amazon Kendra to connect to and index your documents.
Amazon Kendra supports 45+ data sources covering data systems like Aurora(MySQL, PostgreSQL), RDS(MySQL, MS SQL, PostgreSQL), IBM DB2, object storage like S3, source control systems like GitHub, Content Management System like Confluence, Alfresco, Collaborative tools like Slack & Microsoft, Incident Management systems like Jira, Service Now etc.
When you create a data source connector, you give Amazon Kendra the configuration information required to connect to your source repository. Unlike adding documents directly to an index, you can periodically scan the data source to update the index.
Sync Data Source
- Once the data source is created successfully, you will have to sync manually since the demo configuration here is Run On Demand
You will receive the below messageSync started successfully at Mar 15, 2024, 2:41 PM GMT+5:30.
Amazon Kendra is syncing the following data source: 'Intuitive-Webcrawler'. It can take from a few minutes to a few hours. Syncing is a two-step process. First documents are crawled to determine the ones to index. Then the selected documents are indexed. Sync speeds are limited by factors such as remote repository throughput and throttling, network bandwidth, and the size of documents.
-
Failure –
During a demo, showing that everything is "all green" or perfect may not be ideal because it might create unrealistic expectations. In reality, there are often challenges and issues that need to be addressed. It's important to demonstrate a realistic scenario to manage expectations effectively.
I received the following error L
We couldn't sync the following data source: 'Intuitive-Webcrawler', at start time Mar 15, 2024, 2:41 PM GMT+5:30. User: arn:aws:sts::xxxxxxxxx:assumed-role/AmazonKendra-conf/KendraCustomerSession is not authorized to perform: logs:DescribeLogGroups on resource: arn:aws:logs:us-east-1:xxxxxxxxx:log-group::log-stream: because no identity-based policy allows the logs:DescribeLogGroups action (Service: AWSLogs; Status Code: 400; Error Code: AccessDeniedException; Request ID: b94501ca-9981-4d6a-a834-cc759592d027; Proxy: null)Wondering why?
The above recommendation was to create a new role for index but I used the role was created for some other data source.
-
Edit the index, create a new role, update and then run Sync now
Note:
- When you create a new role, as soon as you update the role and click Next, you will get a notification saying role updated successfully.
- In the below screen shot the role name given was AmazonKendra-us-east-1-blog. However you need to pass two more screens (Configure user access control and Add additional capacity) before you reach Review and update.
- Finally when you click the update button, you get the below error which will get you puzzled. No worries, that’s a bug in Amazon Kendra and you can move forward.
Hurray, after 2 failures, hit upon success and don’t miss to look at the total items scanned.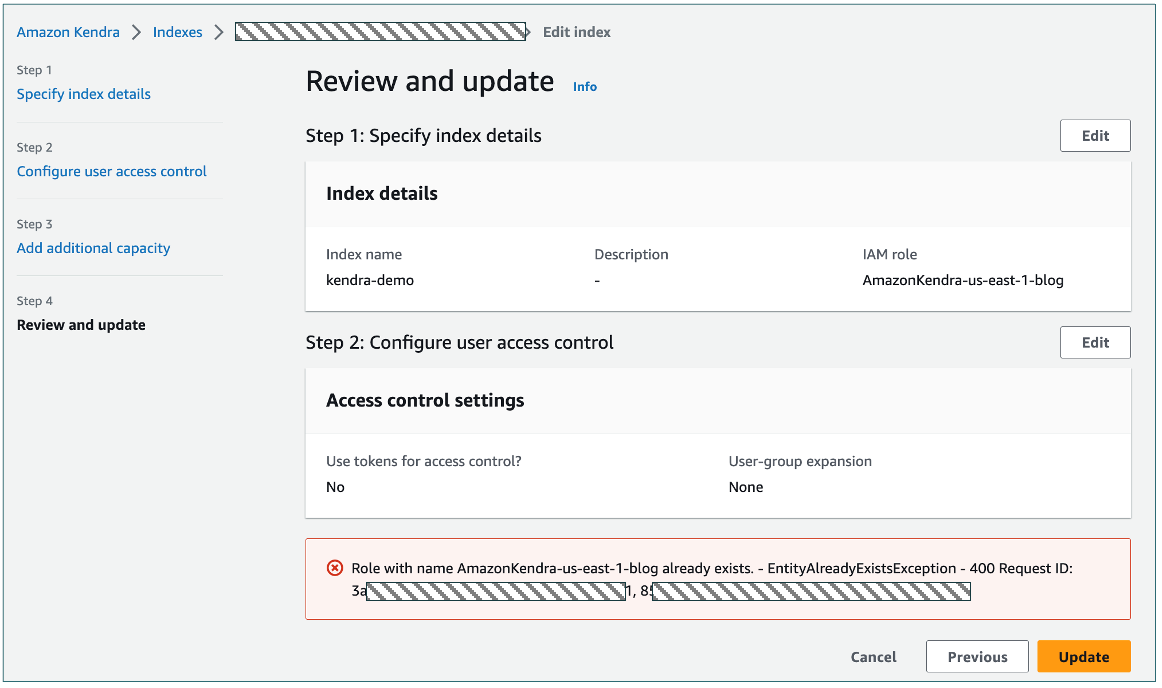
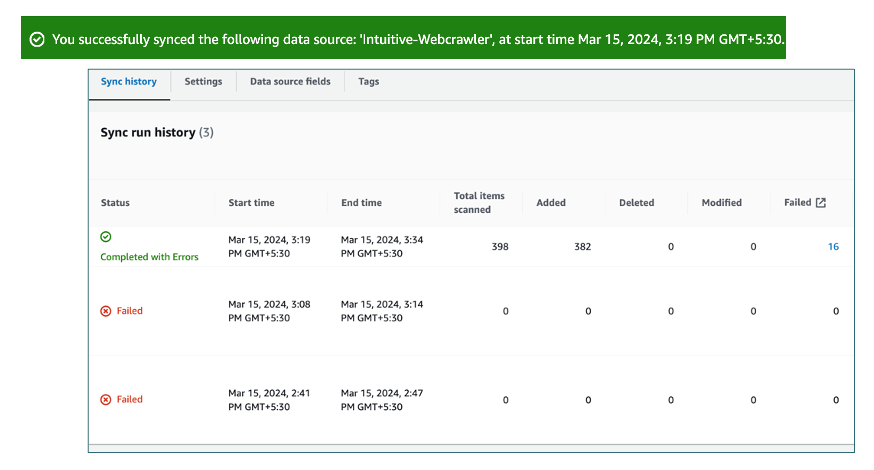
Monitoring & Logging
- Look out for CloudWatch logs which gets created under log groups as /aws/kendra/<kendra index id>
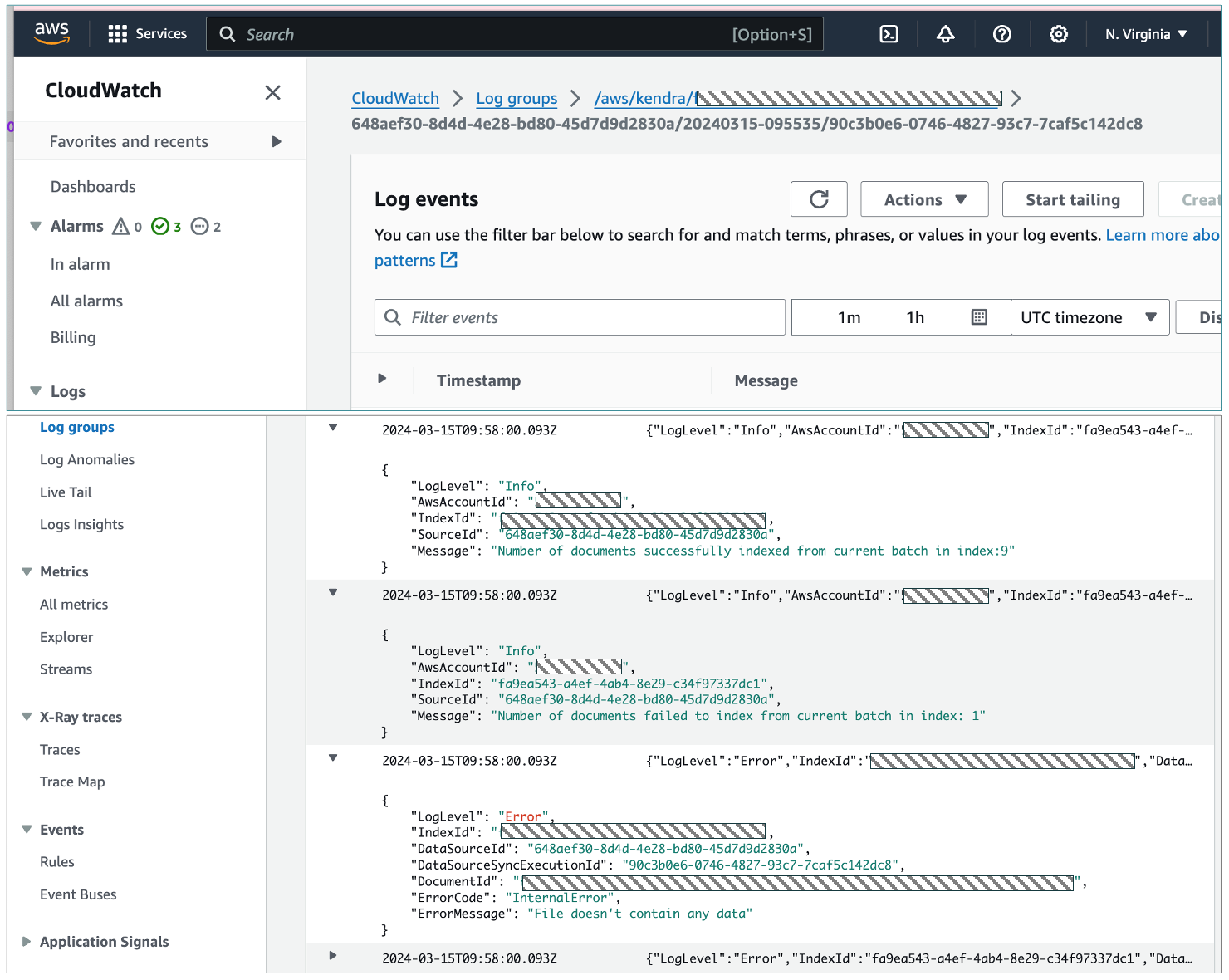
- CloudTrail records all API calls with the Event source, kendra.amazonaws.com.
Experiences
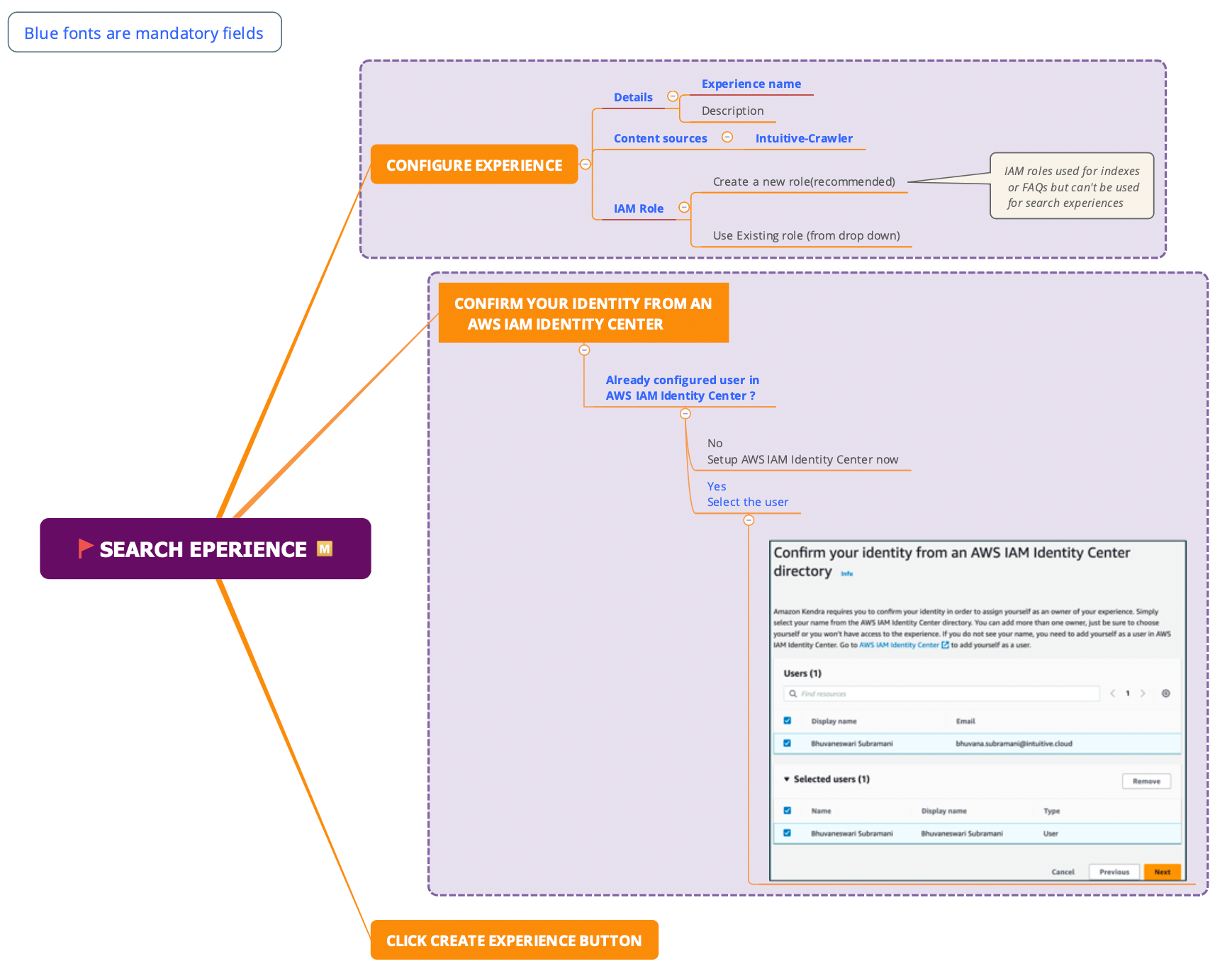
You can build and deploy an Amazon Kendra search application without the need for any front-end code. Amazon Kendra Experience Builder helps you build and deploy a fully functional search application in a few clicks so that you can start searching right away. You can custom design your search page and tune your search to tailor the experience to your users' needs. Amazon Kendra generates a unique, fully hosted endpoint URL of your search page to start searching your documents and FAQs. You can quickly build a proof of concept of your search experience and share it with others.
You use the search experience template available in the builder to customize your search. You can invite others to collaborate in building your search experience, or evaluate search results for tuning purposes. Once your search experience is ready for your users to start searching, you simply share the secure endpoint URL.
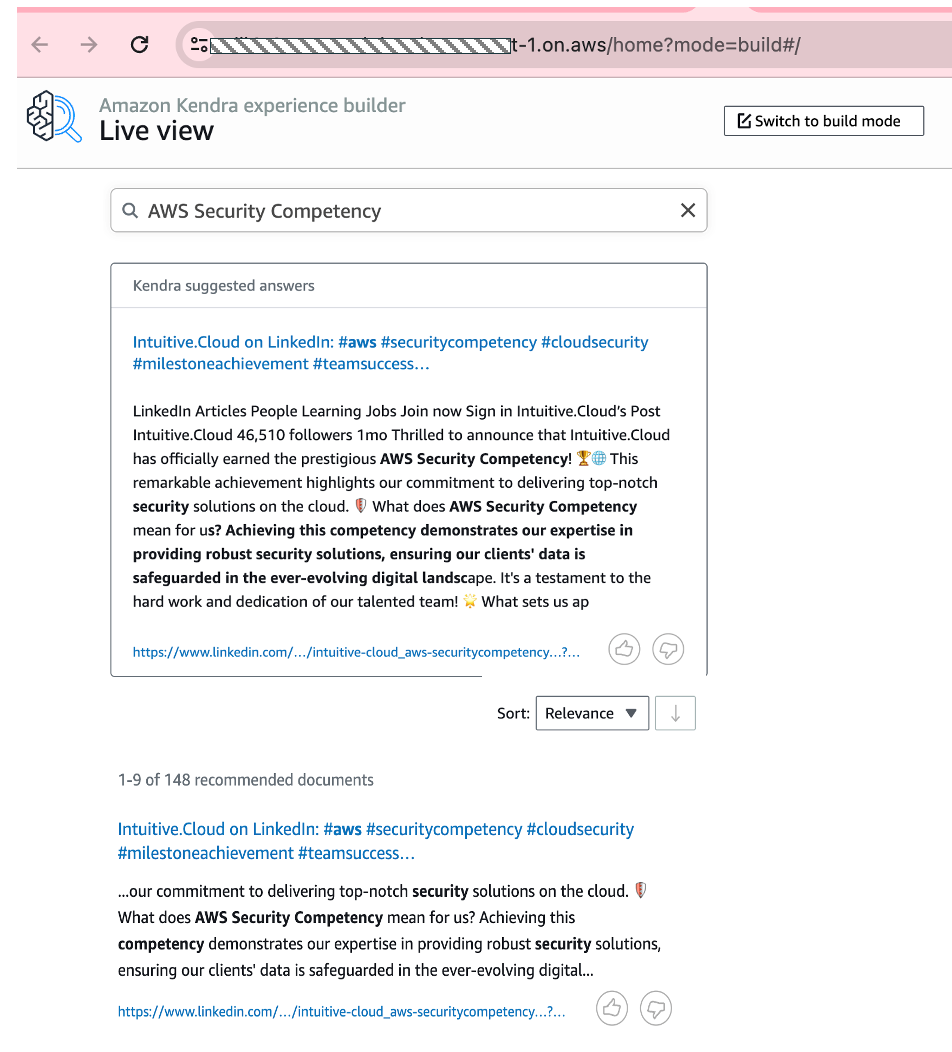
- Let’s experience the search with Amazon Kendra now with the below steps
-
Click the experience URL with the below format a
https://<unique-id>..search.kendra.us-east-1.on.aws/home#/
Clean-up
Kendra Resources
- Go to Amazon Console -> Amazon Kendra Service Note down the 3 roles that you created for index, data source and experience respectively
- Go to Experiences -> Select experience name, click Delete on top right
- Go to Data sources -> Select data source name, click Delete on top right
- Go to index -> Select index name, click Delete on top right
This cool confirmation dialog lets you provide the feedback at the time of deleting any of these resources
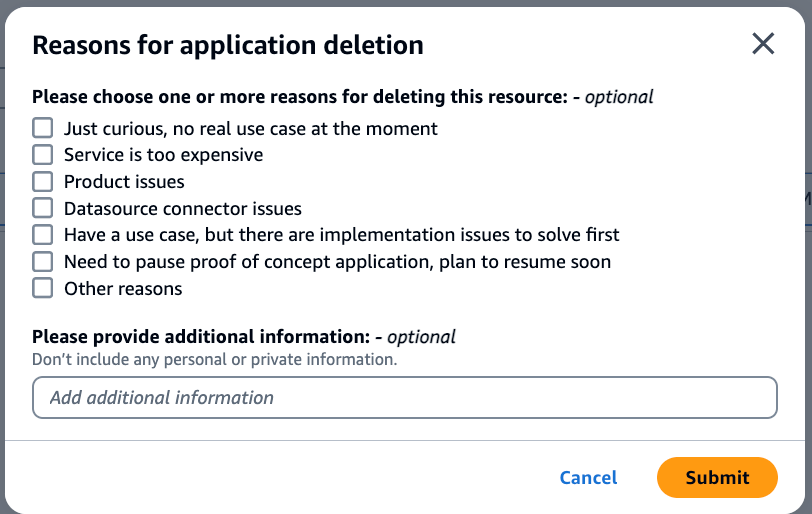
-
Do you want to jump the road and delete the index before data source ?You got that covered. It has been verified when index is deleted before data source, data source is also deleted.
If you are too curious to ask, “how did you verify when you do not see anything on the Amazon Kendra left pane when index itself is deleted?”
I had created an application in Amazon Q integrated with the same data source and peeped into it after the Kendra index was deleted. Got this message!!
Index Id fa9ea543-a4ef-4ab4-8e29-c34f97337dc1 not found for Customer Id 544638597657. - ResourceNotFoundException - 400 Request ID: 448cd1a3-b44c-461b-80fe-b1654c985ec2
That double confirms that deleting index before data source deletes the index.
Roles
- Now the next question – Are the roles deleted automatically?
- That’s No.
- So you go ahead and delete the 3 roles that you created for index, data source and experience respectively
Logs
-
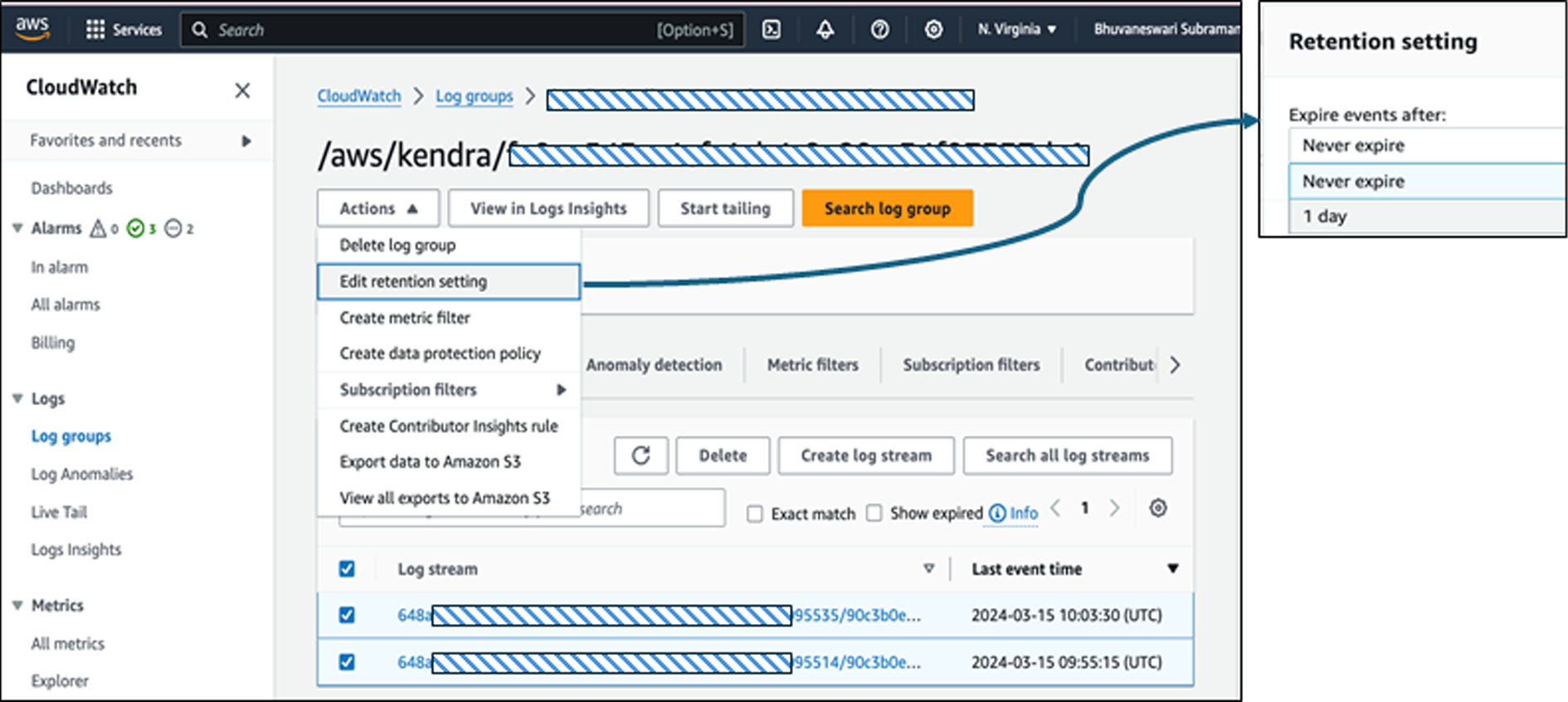
You already saw that Amazon Kendra logs get created in CloudWatch under /aws/kendra/
Does it get cleaned-up automatically? That’s again No.
- By default the CloudWatch log groups that gets created for Amazon Kendra has default retention as Never expire.
- Since you have deleted the Kendra index, it’s time to clean-up CloudWatch logs too. Hence go ahead and change the retention setting to expire by 1 day]
Pricing
The present exploration is with Amazon Kendra Developer Edition which has 750 hrs of free tier for the first 30 days and later priced at $1.125 /hour. Good opportunity to learn and do PoC within 30 days.
Here is the Amazon Kendra service wise billing for this blog exploration.
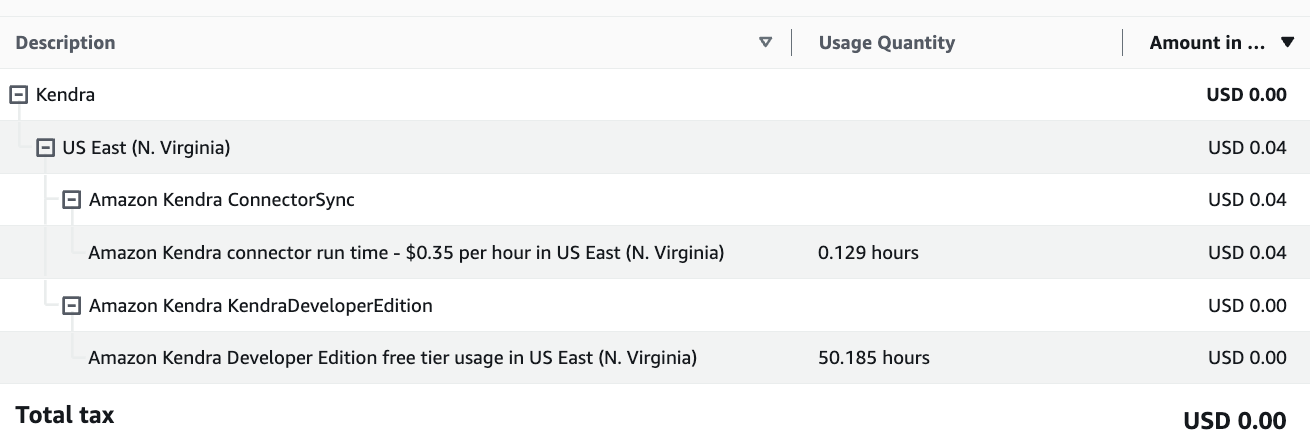
For production workload and enterprise scale, you may look at Enterprise Edition. Refer Kendra Pricing for detailed comparison between Developer Edition and Enterprise Edition.
Roles are different for index, data source and experience. Why & how?
Let’s compare two roles - say the service role for Amazon Kendra Index and Experience to understand better.

Resources
Conclusion
In conclusion, Amazon Kendra offers a powerful solution for enhancing search capabilities for wide variety of data sources. By creating an index, setting up data sources, and crawling data, we have demonstrated how Kendra can significantly improve the search experience. Its advanced machine learning capabilities enable accurate and relevant search results, making it a valuable tool for any organization looking to enhance their search functionality.
