

Disaster Recovery (DR) Solution
Apr 10,2023
Introduction
This case study talks about, a Fortune 500 customer, who is undergoing a cloud transformation journey to build a secure, reliable, and scalable application, data and core infrastructure in cloud and migrate their existing workloads to cloud.
Currently, the customer has 200 production workloads in one of their business unit’s AWS environments and ~700 production workloads in one of their on-premises data center. They were looking for AWS based Disaster Recovery (DR) solution for their overall infrastructure footprint – Cross Region DR for AWS and on-premises to AWS DR for their data center.
Challenges
The customer was operating with lots of business-critical applications on AWS cloud and on-premises DC. For business-critical workloads:
- In on-prem, there was limited capacity DR setup and configured in another DC [manual efforts]
- In cloud, no multi-region DR setup
The current manual and time-intensive DR procedure did not offer the desired levels of recovery timeframes.
The customer was in the process of migrating many mission-critical applications to the AWS EKS platform. The customer was seeking a reliable and effective Disaster Recovery (DR) strategy that keeps their EKS applications in operation with little or no disruption even if an entire Region is unavailable.
Customer wanted to improve application availability & recovery for its business units at on-premises DC & cloud (us-east-1 region) by having its disaster recovery (DR) site to the us-east-2 region of the AWS cloud. For that, the client contacted Intuitive.Cloud for building a DR solution for on-prem, cloud and containerized workloads that ensures their infrastructure recovery with a Recovery Time Objective (RTO) of less than 4 hours and a Recovery Point Objective (RPO) of less than 30 minutes.
Technology Solutions
Cross-Region Cloud DR
Intuitive.Cloud conducted a thorough assessment of the customer’s existing workloads. Tested several Active-Passive and Active-Active Disaster Recovery (DR) methodologies and concluded AWS Elastic Disaster Recovery for Cross Region DR.
AWS Elastic Disaster Recovery supports continuous replication, which means that any changes made in the source environment are reflected in the disaster recovery site within seconds. The customer was able to significantly reduce their recovery time objective (to a few mins), which is the length of time necessary to recover from a disaster after notice of service disruption. It has also significantly reduced its recovery point objective (to a few minutes)—the period that data loss may be tolerated.
Additionally, Intuitive.Cloud team used AWS native backup and recovery feature for other AWS Services:
- MySQL and Postgres on RDS – Cross Region Read Replica
- S3 – Cross-region bucket replication.
- Redis ElastiCache - Backup and Restore (Cross Region Cluster for critical apps)
- OpenSearch – Backup and Restore (Cross Region Cluster for critical apps)
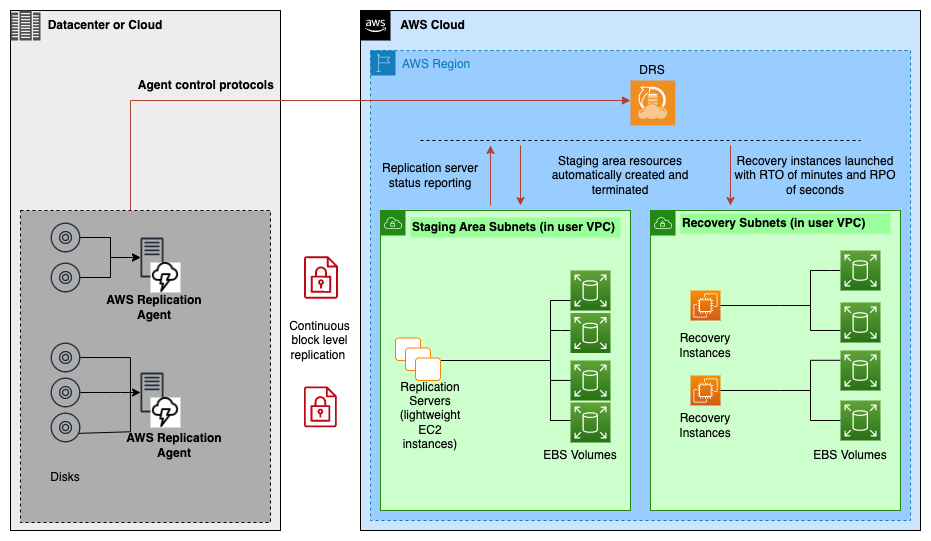
AWS Elastic Disaster Recovery
On-premises DC to Cloud DR
The customer started looking for a solution and started working with Intuitive, an Advanced AWS Consulting Partner, to adopt the CloudEndure Disaster Recovery solution, which minimizes downtime and data loss with quick, dependable recovery of on-premises and cloud-based applications using inexpensive storage, minimal compute, and point-in-time recovery. ITP conducted a thorough assessment of the customer's Disaster Recovery requirements.
Using the CloudEndure DR solution, customer was able to continuously replicate their data in a low-cost staging area on AWS, which reduces its compute and storage footprint to a minimum and reduces the need to provision duplicate resources. By minimizing the costs associated with manual efforts, on-premises hardware, and compute resources, the business unit has optimized its spending on disaster recovery.
AWS EKS DR
Intuitive conducted a thorough assessment of the customer's Disaster Recovery requirements. Based on the requirements, Intuitive cloud chose Velero for EKS DR. Velero is an open-source project providing tools to back up, restore, and migrate your Kubernetes cluster resources and persistent volumes. It is a cloud-native, Kubernetes-optimized approach to backup and restores enabling data protection use cases no matter where your cluster is running. Velero can back up Kubernetes cluster resources and persistent volumes to externally supported storage backend on demand or by schedule. Velero disaster recovery reduces time to recovery in case of infrastructure loss, data corruption, and/or service outages. With the help of this solution, the client can continually replicate Kubernetes objects and persistent volumes (snapshot of EBS volumes) and store the backups in an S3 bucket. These backups are then replicated to the DR region using S3 cross-region replication.
Velero backup and restore operations was declared as Kubernetes Custom Resource Definition (CRD) objects and were managed by controllers that process these new CRD objects to perform backups, restores, and all related operations.
Velero Features
- Back up Clusters - Backup your Kubernetes resources and volumes for an entire cluster, or part of a cluster by using namespaces or label selectors.
- Schedule Backups - Set schedules to automatically kickoff backups at recurring intervals.
- Backup Hooks - Configure pre- and post-backup hooks to perform custom operations before and after Velero backups.
Implementation Strategy
While implementing the DR Solution, automation was used wherever possible:
- Ansible playbook automation used to install the DRS agent in source servers.
- Terraform scripts are used to create networking components like VPC, subnets, route tables, transit gateways etc.
- Terraform scripts used for AWS EKS Cluster provisioning.
- ArgoCD and Helm charts used for deployment of Velero tool.
- Helm charts are used to configure schedules and retention period.
- AWS DRS launch templates are created at scale with the help of Lambda functions.
- AWS CLI automation was used to configure cross-region replication for S3 buckets.
- AWS CLI and python boto3 SDK are used to configure cross-region read replica’s for RDS instances.
- Python scripts and CloudEndure APIs were used to automate and manage the following:
- Authentication
- Replication
- Blueprints
- Launch machines.
- The CloudEndure vCenter Appliance mode is used for VMs at DC.
Results and Impact
- Set up a recovery site in the cloud for 200 EC2 instances. [Cross-region DR]
- Set up a recovery site in the cloud for 900 virtual machines. [On-prem to cloud DR]
- Optimized spending on its disaster recovery process.
- Automated the CloudEndure DR solution using CloudEndure APIs.
- Automated the DR configuration and setup process.
- Eliminated the manual DR process to secondary data center.
- Enhanced the data resiliency and compliance for DC hosted production apps.
- Expanded disaster recovery solution to include all production applications in other regions as well.
- A working BCP plan now exists for production infrastructure with RPO of few mins and RTO of few hours.
Conclusion
In conclusion, this case study highlights the importance of disaster recovery planning for businesses. The successful implementation of the disaster recovery plan was due to the customer’s commitment to regularly reviewing and testing the plan to ensure its effectiveness. This case study serves as a reminder to customer’s business units of all sizes to prioritize disaster recovery planning to mitigate the risk of unforeseen events. By investing in disaster recovery planning and testing, businesses can protect themselves from potential data loss and minimize the impact of outages on their operations, reputation, and bottom line.
