

Helped one of the leading Telecommunication Providers improve Customer Experience and Customer Retention
May 31, 2023
Introduction:
In this study, we focused on a client who is a telecommunications services provider such as mobile and broadband. The study’s main objective was to understand subscriber churn behavior and come up with proactive strategies to improve the customer experience and customer retention. Intuitive assisted the customer through the entire technology from data to machine learning lifecycle to identify at-risk customers and recommended intervention strategies to achieve the company’s business objectives.
Challenges
The company faced several significant challenges when it came to deriving actionable insights from the vast amount of customer data it had collected. The first hurdle they encountered was the sheer volume and complexity of the data stored in their database, encompassing a wide range of customer information such as purchase history, browsing behavior, and feedback. The scale of this data posed difficulties in processing and analyzing it efficiently, making it challenging to extract meaningful insights.
In their efforts to leverage predictive modeling, the company confronted issues with their existing model's performance stability. They observed significant variations in the model's effectiveness over time with even minor changes in input data. The lack of consistent and reliable results hindered their ability to derive accurate and actionable insights from the customer data they had amassed. In addition, we identified and informed the client that the model has major performance issues in terms of False Negative Rate. It was also noted that using a single model for all the products offered by the client could have resulted in potential performance degradation.
Furthermore, the company identified a critical limitation in the interpretability of their predictive models. Without a clear understanding of the reasoning behind the models' predictions, it became challenging to explain and comprehend the insights they generated. This interpretability gap acted as a barrier to translating these insights into actionable strategies and decision-making processes.
Another pressing challenge the company faced was the brittle architecture on which their churn model was built. This architectural fragility introduced the risk of potential information leakage, putting sensitive customer data at stake and compromising privacy. Recognizing the gravity of this issue, the company recognized the need to rectify the architecture's vulnerabilities and ensure the security of customer data.
To address these challenges comprehensively, the company embarked on a transformative initiative to establish an end-to-end MLOps (Machine Learning Operations) process on the AWS platform. This MLOps solution aimed to automate their modeling, retraining, inference, and monitoring processes, providing a scalable and efficient framework for their data-driven insights. By embracing automation and scalability, the company sought to enhance their ability to process and derive valuable insights from their customer data while ensuring the security and privacy of sensitive information.
Technology Solutions
To fully grasp the customer's business perspective, extensive time and effort were dedicated to understanding their unique requirements and objectives. This involved close collaboration with the customer's data scientists and marketing team, delving into their existing data infrastructure, processes, and analytical models. Key accomplishments during this phase included clarifying business objectives in relation to the model's outputs, reframing the problem to align better with those objectives, identifying relevant data sources, comprehending the creation of machine learning datasets, and reformulating pipelines to generate the required datasets.
Following the creation of datasets, a collaborative effort with the data scientist team ensued to establish performance boundaries for existing models. We performed a detailed model error analysis to identify the model limitation and performance for each customer segment. Precise performance baselines were defined to assess the predictive value of new model architectures. Novel model architectures were then constructed, trained on updated datasets, and subjected to meticulous hyperparameter tuning. Alongside model development, a comprehensive roadmap was devised, encompassing deployment strategies, model monitoring techniques, and sensitivity analysis. This systematic approach ensured a professional and organized process for model development and implementation. We also proposed methods for the client to understand the importance of the features used by the model and the underlying reason for each customer that is predicted to churn. This was later used as a basis to propose incentive and mitigation measures for customer retention.
For data storage, the company utilized Snowflake as their data lake, while leveraging the comprehensive Amazon SageMaker ecosystem for the remaining machine learning workflow. Initially, pipelines and model architectures underwent evaluation on a smaller, ad hoc scale to address any potential issues. Once concerns were resolved, the pipelines and models were trained at scale using Snowflake and SageMaker, ensuring a seamless integration of the data lake and machine learning platforms. This approach facilitated efficient and effective model training on large-scale datasets, contributing to the overall success of the project. The technologies used to deliver the solution were: AWS SageMaker, AWS Clarify, Snowflake, LIME, XGBoost, Sklrean, S3 buckets, AWS CodeCommit, CodeBuild, CodePipeline, Elastic Container Registry (ECR), and CloudFormation.
Implementation Strategy
To ensure effective project execution and deliver valuable outcomes, an Agile methodology was employed, prioritizing tangible outputs.
To address the challenge of making existing data more interpretable for the model, several modifications were recommended. This included simplifying feature categories, computing aggregations based on fixed-width windows, framing the problem with dynamic churn and probabilistic interpretations of churn probability, converting object-type features to appropriate types, adopting a simpler schema for demographic and revenue information extraction, and implementing granular event capture and separate metrics table creation. Additionally, suggestions were made to include more features initially and perform feature selection and regularization within the model, address missing data, guard against information leakage through end-to-end pipelines, and remove potential encoded information from model inputs. Furthermore, it was proposed to develop a more disaggregate model for specific groups of products offered by the client based on the results of the error analysis. The error analysis also identified that even though the client deemed that the model had a good performance, based on model accuracy, it actually had a very high False Negative Rate, suggesting that it was unable to identify many of the customers who churned.
To analyze model explainability and bias, the usage of SageMaker Clarify as part of the model training pipeline was recommended. SageMaker Clarify interacts with an Amazon S3 bucket and supports various analysis types such as pre-training and post-training bias metrics, SHAP values, Partial Dependence Plots (PDP), and feature attributions. Additionally, global and local model agnostic methods were employed to analyze model sensitivity and identify significant factors contributing to customer churn. LIME was suggested for individual churn prediction explanations, and an algorithmic method inspired by adversarial attacks was proposed to identify impactful features for churn mitigation. Regular model retraining was proposed to ensure accuracy and relevance, involving data collection, preprocessing, feature engineering using AWS DataWrangler, training with the XGBoost algorithm, and evaluation using suitable metrics. Techniques like cross-validation, hyperparameter tuning, ensemble methods, and the inclusion of SageMaker Clarify and SageMaker Debugger were recommended to improve the model and mitigate training errors and bias. The proposed solution is shown below.
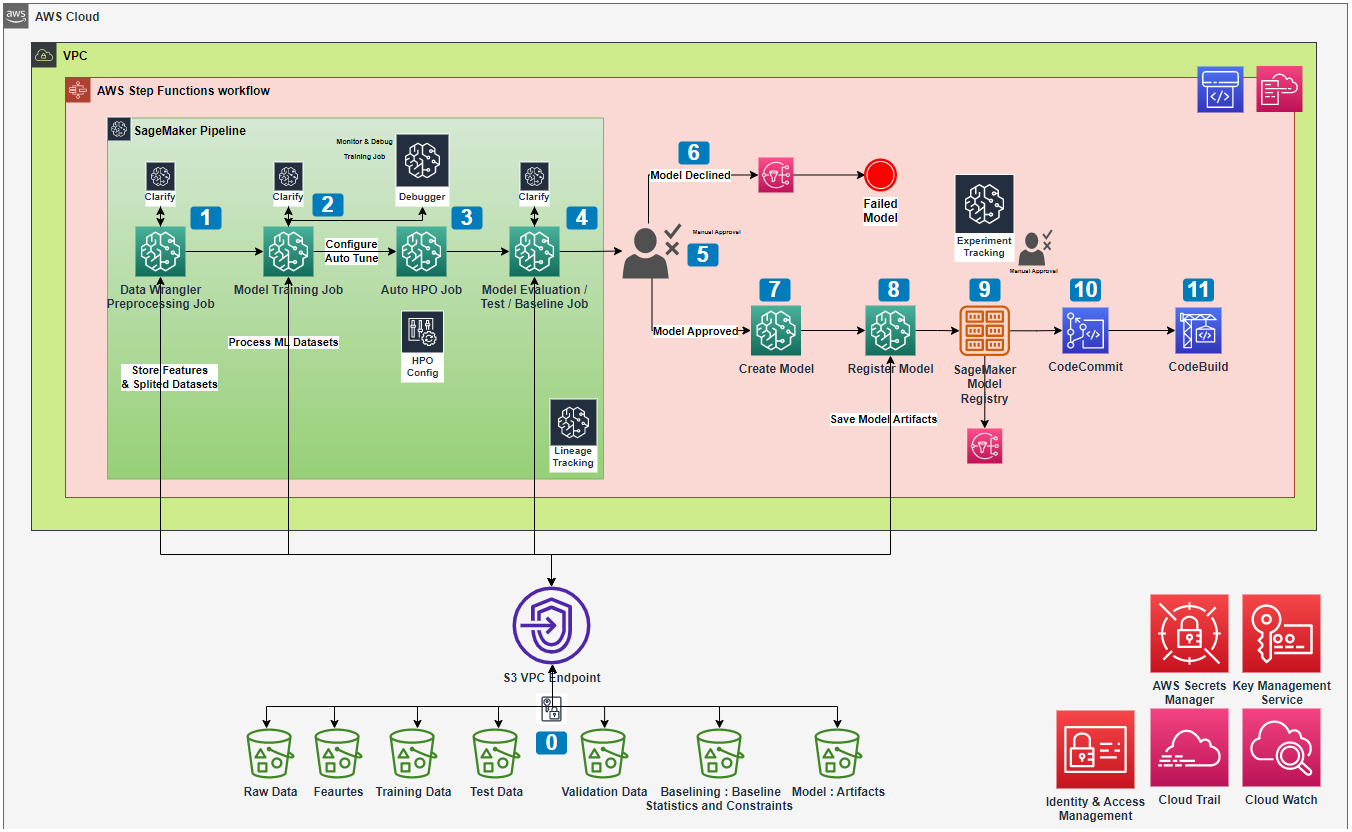
To ensure effective monitoring and inference of churn predictions, we proposed the implementation of a robust model monitoring and inference pipeline. This involves continuously tracking key metrics and setting up alerts to detect any significant deviations in the performance of the churn prediction model. For automated inference on new data, we suggested utilizing Batch Transform Job, which allows for efficient processing of input data. Furthermore, we recommended integrating interpretability techniques such as feature importance analysis, partial dependence plots, or LIME explanations to gain insights into the decision-making process of the model. By establishing a well-designed system for model monitoring and inference, businesses can extract actionable insights from churn predictions and make informed decisions to effectively mitigate customer churn.
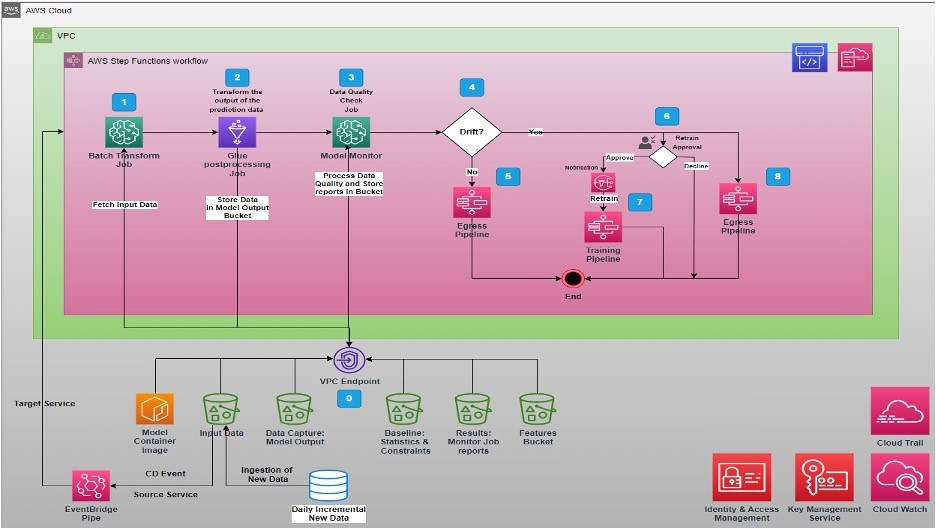
In addition, we advised incorporating Continuous Integration and Continuous Delivery (CI/CD) tools such as AWS CodeCommit, CodeBuild, CodePipeline, Elastic Container Registry (ECR), and CloudFormation. These tools enable a smooth and automated process from model training to deployment, ensuring the efficient and effective generation of predictions on data. By leveraging CI/CD practices, organizations can streamline their workflows, automate version control, build and test models, and deploy them with ease, enhancing the overall prediction capabilities and facilitating timely decision-making.
Results and Impact
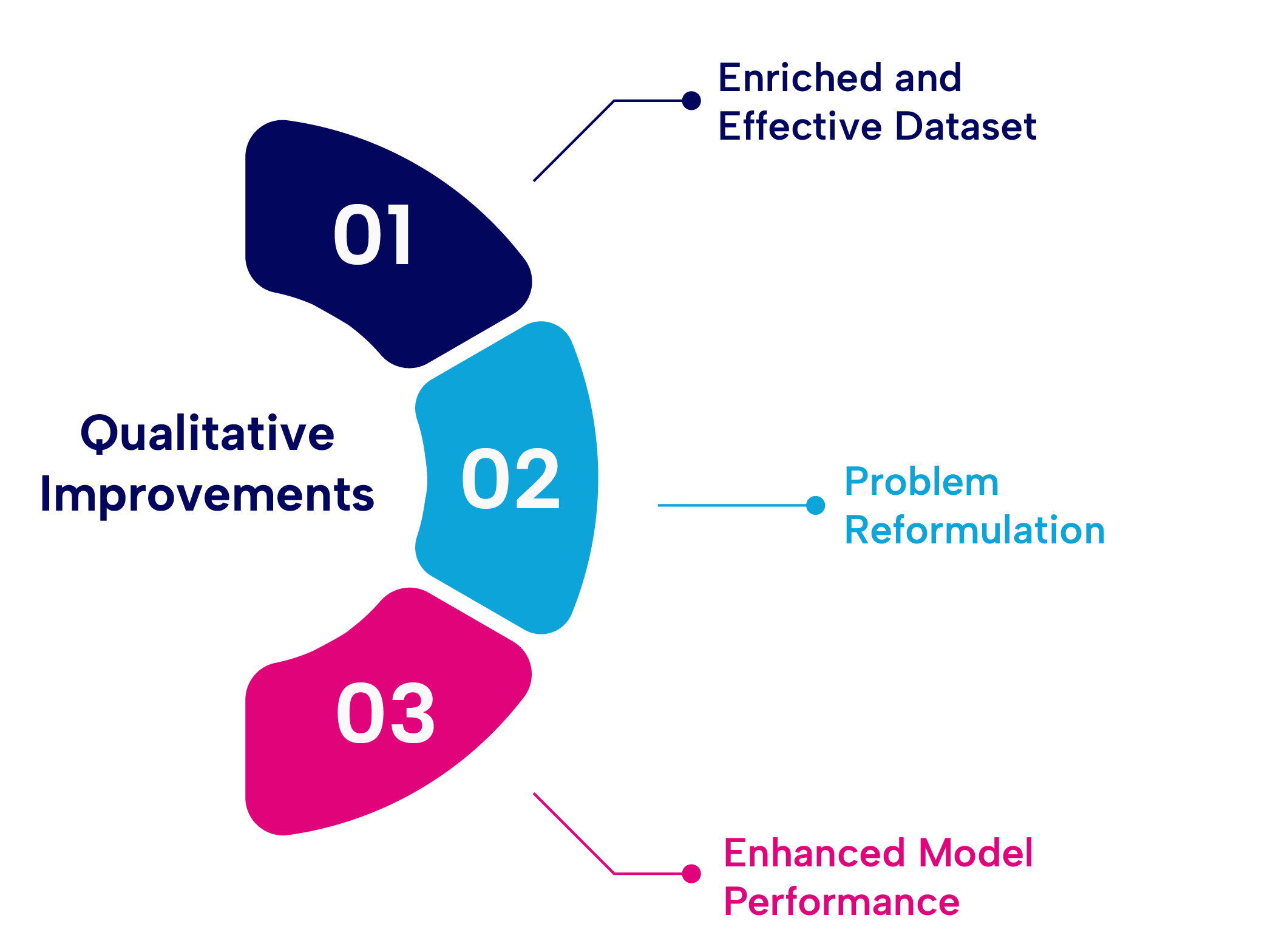
The project resulted in significant improvements in both qualitative and quantitative aspects of the existing models.
Qualitative Improvements:
- Enriched and Effective Dataset: The process of creating the model dataset provided valuable insights into customer metrics and disposition, enhancing the overall quality and usefulness of the dataset. This enriched dataset enabled better understanding and analysis of customer behavior, leading to more informed decision-making.
- Problem Reformulation: A key aspect of the project involved reevaluating the collection and utilization of operational metrics, leading to significant changes. By introducing a segmentation, changes in performance measures, probabilistic and time-windowed approach to customer churn, the models' predictions became more actionable. This reformulation allowed the business to strategically allocate marketing resources and prioritize efforts more effectively.
- Enhanced Model Performance: The model demonstrated a significant improvement in performance, achieving a twofold enhancement when evaluated against benchmarks specifically designed for imbalanced datasets. This improvement in model performance translated into more accurate and reliable predictions, contributing to the overall effectiveness of the churn prediction system.
Overall, the project's insights and optimizations brought about qualitative enhancements in dataset quality and problem formulation, while quantitatively improving the model's performance, leading to more actionable and accurate predictions for the business.
Lessons Learned
The successful completion of this project was the result of a collaborative effort between the client and the consultant, overcoming various technical challenges across security, governance, engineering, and machine learning domains.
The process of problem framing and formulation played a pivotal role in laying the groundwork for the project's success. Without a well-defined problem statement, the subsequent stages and activities would lack clarity and purpose, undermining their value.
Demonstrating the value of the solution on smaller scales before scaling the training infrastructure was a crucial step in determining the optimal path forward. Robust model error analysis and data hygiene were vital for achieving the business objectives. Establishing traceability throughout the machine learning workflow was essential in building trust and promoting widespread adoption of the solution. Effective communication with stakeholders, using clear and concise language and through working sessions, was imperative to maintain their engagement and encourage their active involvement.
Conclusion
The collaborative effort between the client and the consultant in this telecommunications project resulted in significant improvements in both qualitative and quantitative aspects of the existing churn prediction models. Challenges related to data volume, model performance stability, interpretability limitations, and architectural vulnerabilities were addressed through the implementation of an end-to-end MLOps process on the AWS platform. This comprehensive approach allowed the client to extract valuable insights from their data and make proactive decisions to improve customer retention.
Qualitatively, the project enriched the dataset and reformulated the problem, leading to a better understanding of customer behavior and more actionable predictions. Quantitatively, the model's performance showed a twofold enhancement compared to benchmarks for imbalanced datasets, resulting in more accurate churn predictions. Lessons learned emphasized the importance of problem framing, demonstrating value on smaller scales, robust error analysis, data hygiene, and effective communication with stakeholders.
