

Build Highly Available Big Data Platform on Hadoop – The Hard Way
By Bikram Singh / Apr 02,2018
Overview
This blog takes a longer path to configure Highly Available Big Data platform on Hadoop using purely command line. There are GUI tools exists like Ambari or Cloudera manager which helps you to build and manage Hadoop clusters, however focus of this blog will be to learn how high-availability in Hadoop is configured and you have the control on each configuration parameter being configured, I will call it Hadoop the hard way. I will not be discussing the architecture of Hadoop and its components, however you should have an understanding of Hadoop architecture and its components before proceeding. I highly recommend going through below docs before start configuring the hadoop cluster.
Hadoop Cluster Components
- Hadoop 2.9.0 – from hadoop.apache.org
- Zookeeper 3.4.11
- CentOS 7.3 x86_64 as base OS
- All the nodes in the cluster are Virtual Machines
- Hadoop cluster is running on Openstack.
Prerequisites
To complete this article, you will need below Infrastructure: I have build this infrastructure for lab, however if you plan to build for production please refer to the Hadoop documentation for hardware recommendations: Below is for Hortonworks
Hortonworks Hadoop Cluster Planning Guide
- CentOS x86_64_7.3.1611-Minimal for all the nodes.
- 2x Hadoop NameNodes – 4GB RAM and 2vCPU
- 3x Yarn ResourceManager nodes – 4GB RAM and 2vCPU
- 3x JournalNodes – 4GB RAM and 2vCPU
- 3x ZookeeperNodes – 4GB RAM and 2vCPU
- 3x Hadoop DataNodes – 6GB RAM and 4vCPU
- DNS – Both forward and reverse lookup enabled
- JDK installed on all the nodes – I used jdk-8u151
- If you have firewall between servers then make sure all the Hadoop service ports are open. You can refer below as a reference or if you plan to use custom ports then make sure are they are allowed via firewall.
- Hadoop Service Ports
High level Cluster Architecture
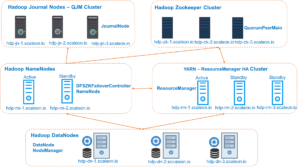
Hadoop NameNodes
hdp-nn-1.scaleon.io -- 172.16.10.74
hdp-nn-2.scaleon.io -- 172.16.10.16
Services Running on these nodes
-DFSZKFailoverController
-NameNodeHadoop DataNodes
hdp-dn-1.scaleon.io -- 172.16.10.42
hdp-dn-2.scaleon.io -- 172.16.10.75
hdp-dn-3.scaleon.io -- 172.16.10.46
Services Running on these nodes
-DataNode
-NodeManagerHadoop JournalNodes – QJM Cluster
hdp-jn-1.scaleon.io -- 172.16.10.72
hdp-jn-2.scaleon.io -- 172.16.10.70
hdp-jn-3.scaleon.io -- 172.16.10.82
Services Running on these nodes
-JournalNodeHadoop YARN ResourceManager Nodes
hdp-rm-1.scaleon.io -- 172.16.10.42
hdp-rm-2.scaleon.io -- 172.16.10.75
hdp-rm-3.scaleon.io -- 172.16.10.46
Services Running on these nodes
-ResourceManagerHadoop Zookeeper Nodes
hdp-zk-1.scaleon.io -- 172.16.10.48
hdp-zk-2.scaleon.io -- 172.16.10.79
hdp-zk-3.scaleon.io -- 172.16.10.73
Services Running on these nodes
-QuorumPeerMainConfigure the Hadoop Cluster
NameNodes
We will configure NameNode/HDFS High Availability (HA) using the Quorum Journal Manager (QJM) feature.
In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast failover if necessary.
In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called “JournalNodes” (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the JounalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs.
In order to provide a fast failover, it is also necessary that the Standby node have up-to-date information regarding the location of blocks in the cluster. In order to achieve this, the DataNodes are configured with the location of both NameNodes, and send block location information and heartbeats to both.
It is vital for the correct operation of an HA cluster that only one of the NameNodes be Active at a time. Otherwise, the namespace state would quickly diverge between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called “split-brain scenario,” the JournalNodes will only ever allow a single NameNode to be a writer at a time. During a failover, the NameNode which is to become active will simply take over the role of writing to the JournalNodes, which will effectively prevent the other NameNode from continuing in the Active state, allowing the new Active to safely proceed with failover.
Ref : HDFS HA
Install JDK on all the Nodes with below command
rpm -ivh jdk-8u151-linux-x64.rpmDownload and untar Hadoop binaries on hdp-nn-1
sudo wget https://archive.apache.org/dist/hadoop/core/hadoop-2.9.0/hadoop-2.9.0.tar.gz
tar –xvf hadoop-2.9.0.tar.gz
Add JAVA_HOME,YARN,HADOOP and ZOOKEEPER env variable in .bashrc file
make sure you update correct path based on location where you have stored the files
cat ~/.bashrc
#.bashrc
#Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
#Uncomment the following line if you don't like systemctl's auto-paging feature:
#export SYSTEMD_PAGER=
#User specific aliases and functions
export HADOOP_HOME=/home/centos/hadoop-2.9.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/usr/java/jdk1.8.0_151
export ZOOKEEPER_HOME=/home/centos/zookeeper-3.4.11
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
Now we need to enable password less SSH to all the nodes from both the NameNodes, there are many ways like ssh-copy-id or manually copying the keys, do the way you prefer. I have generated the SSH Key and copied using SSH.
[centos@hdp-nn-1 ~]$ sudo ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
85:fb:83:f8:35:c7:8f:9a:02:91:34:48:9b:d1:2f:81 root@hdp-nn-1
The key's randomart image is:
+--[ RSA 2048]----+
| .o+ |
| E+= . |
| o. =. . |
| + .o |
| oS |
| .. o . |
| ... = o |
| ... = o |
| ..o.. . |
+-----------------+
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'
sudo cat /root/.ssh/id_rsa.pub | ssh -i cloud4.pem -o StrictHostKeyChecking=no [email protected] 'cat >> ~/.ssh/authorized_keys'Repeate this SSH key copy step from hdp-nn2 also.
Configure core-site.xml file located at /home/centos/hadoop-2.9.0/etc/hadoop as per below :
For details on properties and their values configured please refer below documentation
Ref : HDFS HA
[centos@hdp-nn-1 hadoop]$ cat core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdpdev-cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/centos/hadoop/journaldata</value>
</property>
</configuration>
[centos@hdp-nn-1 hadoop]$Configure hdfs-site.xml as per below :
For details on properties and their values configured please refer below documentation
Ref : HDFS HA
[centos@hdp-nn-1 hadoop]$ cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/centos/hadoop/nndata</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hdpdev-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.hdpdev-cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdpdev-cluster.nn1</name>
<value>hdp-nn-1.scaleon.io:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdpdev-cluster.nn2</name>
<value>hdp-nn-2.scaleon.io:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.hdpdev-cluster.nn1</name>
<value>hdp-nn-1.scaleon.io:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hdpdev-cluster.nn2</name>
<value>hdp-nn-2.scaleon.io:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp-jn-1.scaleon.io:8485;hdp-jn-2.scaleon.io:8485;hdp-jn-3.scaleon.io:8485/hdpdev-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hdpdev-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp-zk-1.scaleon.io:2181,hdp-zk-2.scaleon.io:2181,hdp-zk-3.scaleon.io:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
[centos@hdp-nn-1 hadoop]$
Configure mapred-site.xml as per below:
[centos@hdp-nn-1 hadoop]$ cat mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[centos@hdp-nn-1 hadoop]$Now Copy this hadoop-2.9.0 folder to all the nodes in the cluster
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/
sudo scp -r hadoop-2.9.0/ [email protected]:/home/centos/ZookeeperNodes
Download and untar zookeeper binaries. Edit Zookeeper configuration file located at /home/centos/zookeeper-3.4.11/conf
You need to configure 2 parameters dataDir and Server, replace them with your values
sudo wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
tar –xvf zookeeper-3.4.6.tar.gz
cd /home/centos/zookeeper-3.4.11/conf
sudo cp zoo_sample.cfg zoo.cfg
[centos@hdp-nn-1 conf]$ cat zoo.cfg
#The number of milliseconds of each tick
tickTime=2000
#The number of ticks that the initial
#synchronization phase can take
initLimit=10
#The number of ticks that can pass between
#sending a request and getting an acknowledgement
syncLimit=5
#the directory where the snapshot is stored.
#do not use /tmp for storage, /tmp here is just
#example sakes.
dataDir=/home/centos/hadoop/zk
#the port at which the clients will connect
clientPort=2181
#the maximum number of client connections.
#increase this if you need to handle more clients
#maxClientCnxns=60
#Be sure to read the maintenance section of the
#administrator guide before turning on autopurge.
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
#Purge task interval in hours
#Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hdp-zk-1.scaleon.io:2888:3888
server.2=hdp-zk-2.scaleon.io:2888:3888
server.3=hdp-zk-3.scaleon.io:2888:3888
[centos@hdp-nn-1 conf]$Repeat above for all the Zookeeper nodes
Create a myid file at Zookeeper location dataDir=/home/centos/hadoop/zk on all 3 nodes
[centos@hdp-zk-1 ~]$ cat /home/centos/hadoop/zk/myid
1
[centos@hdp-zk-2 ~]$ cat /home/centos/hadoop/zk/myid
2
[centos@hdp-zk-3 ~]$ cat /home/centos/hadoop/zk/myid
3Start Hadoop Services
Hadoop JournalNodes – hdp-jn-1, hdp-jn-2, hdp-jn-3
hadoop-daemon.sh start journalnode
[root@hdp-jn-1 centos]# jps
5796 Jps
2041 JournalNode
[root@hdp-jn-1 centos]#
[root@hdp-jn-2 centos]# jps
1964 JournalNode
5741 Jps
[root@hdp-jn-2 centos]#
[root@hdp-jn-3 centos]# jps
5762 Jps
1942 JournalNode
[root@hdp-jn-3 centos]#Zookeeper Nodes- hdp-zk-1, hdp-zk-2, hdp-zk3
zkServer.sh start
[root@hdp-zk-1 centos]# jps
5907 Jps
5876 QuorumPeerMain
[root@hdp-zk-1 centos]#
[root@hdp-zk-2 centos]# jps
5926 Jps
5879 QuorumPeerMain
[root@hdp-zk-2 centos]#
[root@hdp-zk-3 centos]# jps
5872 Jps
5807 QuorumPeerMain
[root@hdp-zk-3 centos]#Hadoop Active NameNode – hdp-nn-1.scaleon.io
hdfs namenode -format
hadoop-daemon.sh start namenode
hdfs zkfc –formatZK
hadoop-daemon.sh start zkfc
[root@hdp-nn-1 centos]# jps
28977 Jps
3738 DFSZKFailoverController
3020 NameNode
[root@hdp-nn-1 centos]#Hadoop Standby NameNode – hdp-nn-2.scaleon.io
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
hdfs zkfc –formatZK
hadoop-daemon.sh start zkfc
[root@hdp-nn-2 centos]# jps
2708 NameNode
3166 DFSZKFailoverController
2191 Jps
[root@hdp-nn-2 centos]#
[root@hdp-nn-1 centos]# hdfs haadmin -getServiceState nn1
active
[root@hdp-nn-1 centos]# hdfs haadmin -getServiceState nn2
standby
[root@hdp-nn-1 centos]#
Hadoop Yarn ResourceManager Nodes – hdp-rm-1, hdp-rm-2, hdp-rm-3
yarn-daemon.sh start resourcemanager
[root@hdp-rm-1 centos]# jps
8570 ResourceManager
9131 Jps
[root@hdp-rm-1 centos]#
[root@hdp-rm-2 ~]# jps
8937 ResourceManager
9244 Jps
[root@hdp-rm-2 ~]#
[root@hdp-rm-3 sbin]# jps
8994 ResourceManager
9291 Jps
[root@hdp-rm-3 sbin]#
[root@hdp-rm-1 centos]# yarn rmadmin -getServiceState rm1
active
[root@hdp-rm-1 centos]# yarn rmadmin -getServiceState rm2
standby
[root@hdp-rm-1 centos]# yarn rmadmin -getServiceState rm3
standby
[root@hdp-rm-1 centos]#
Hadoop DataNodes – hdp-dn-1, hdp-dn-2, hdp-dn-3
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
[root@hdp-dn-1 sbin]# jps
3346 DataNode
9143 NodeManager
9852 Jps
[root@hdp-dn-1 sbin]#
[root@hdp-dn-2 sbin]# jps
2518 DataNode
8167 NodeManager
9575 Jps
[root@hdp-dn-2 sbin]#
[root@hdp-dn-3 sbin]# jps
9590 Jps
8361 NodeManager
2815 DataNode
[root@hdp-dn-3 sbin]#Verification
Active NameNode

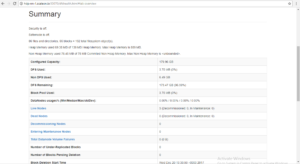
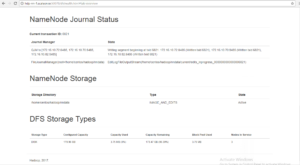

Standby NameNode

 .
.

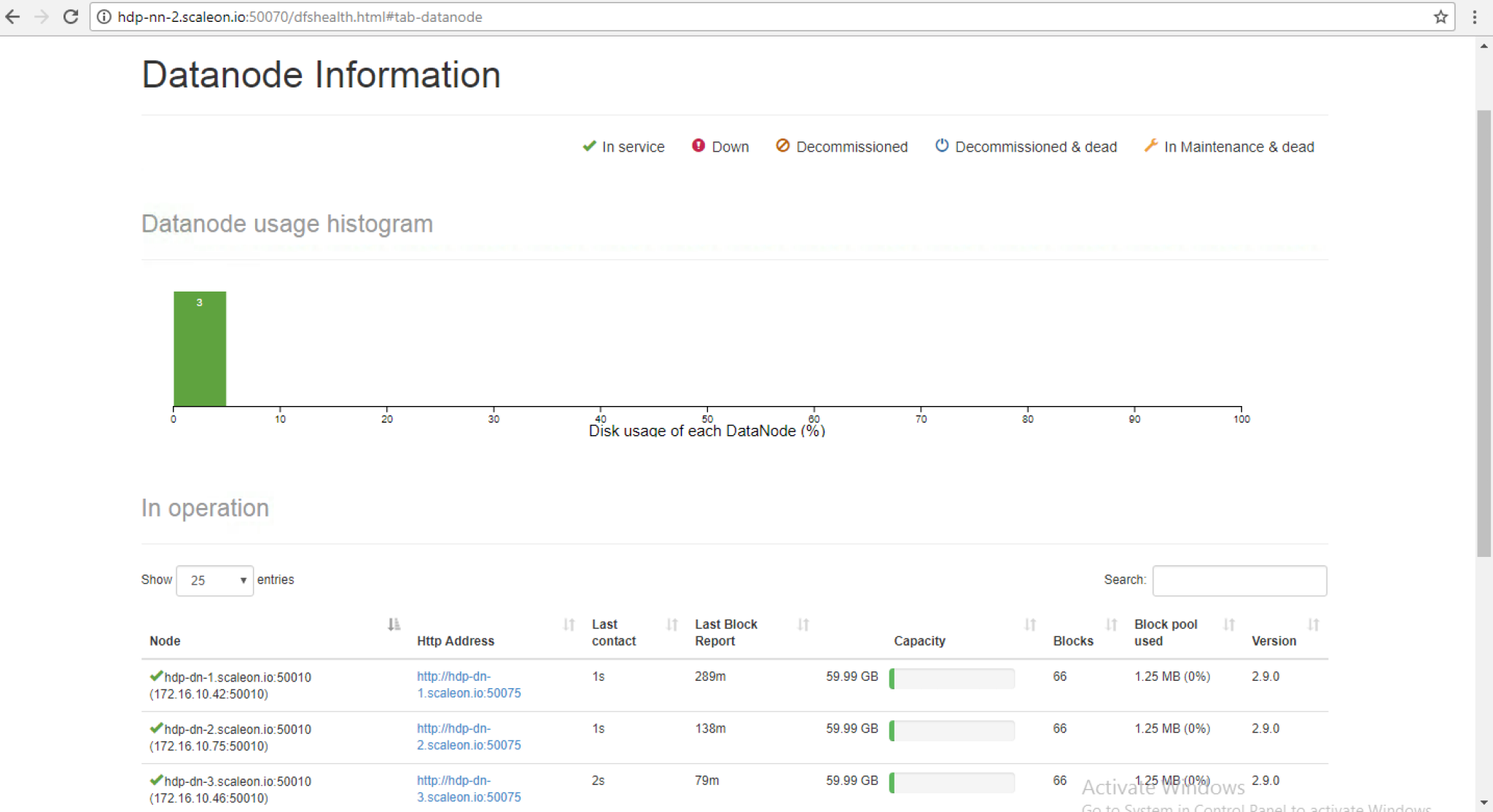
Now lets submit a basic wordcount MapReduce Job to validate that our Hadoop cluster is working as expected and can store data on HDFS and perform computation, this way we will also be able to validate if our YARN – ResourceManager is able to schedule and manage MapReduce jobs.
I will create a directory called “input” on HDFS and then copy all the contents from my local /home/centos/hadoop-2.9.0/etc/hadoop/ to it and run a MapReduce job to count words starting with “dfs.”
[root@hdp-nn-1 hadoop-2.9.0]# pwd
/home/centos/hadoop-2.9.0
[root@hdp-nn-1 hadoop-2.9.0]# bin/hdfs dfs -mkdir /input
[root@hdp-nn-1 hadoop-2.9.0]# bin/hdfs dfs -put etc/hadoop/* /input/
[root@hdp-nn-1 hadoop-2.9.0]# bin/hdfs dfs -ls /input/hadoop
Found 29 items
-rw-r--r-- 3 root supergroup 7861 2017-12-22 12:14 /input/hadoop/capacity-scheduler.xml
-rw-r--r-- 3 root supergroup 1335 2017-12-22 12:14 /input/hadoop/configuration.xsl
-rw-r--r-- 3 root supergroup 1211 2017-12-22 12:14 /input/hadoop/container-executor.cfg
-rw-r--r-- 3 root supergroup 978 2017-12-22 12:14 /input/hadoop/core-site.xml
-rw-r--r-- 3 root supergroup 3804 2017-12-22 12:14 /input/hadoop/hadoop-env.cmd
-rw-r--r-- 3 root supergroup 4666 2017-12-22 12:14 /input/hadoop/hadoop-env.sh
-rw-r--r-- 3 root supergroup 2490 2017-12-22 12:14 /input/hadoop/hadoop-metrics.properties
-rw-r--r-- 3 root supergroup 2598 2017-12-22 12:14 /input/hadoop/hadoop-metrics2.properties
-rw-r--r-- 3 root supergroup 10206 2017-12-22 12:14 /input/hadoop/hadoop-policy.xml
-rw-r--r-- 3 root supergroup 2515 2017-12-22 12:14 /input/hadoop/hdfs-site.xml
-rw-r--r-- 3 root supergroup 2230 2017-12-22 12:14 /input/hadoop/httpfs-env.sh
-rw-r--r-- 3 root supergroup 1657 2017-12-22 12:14 /input/hadoop/httpfs-log4j.properties
-rw-r--r-- 3 root supergroup 21 2017-12-22 12:14 /input/hadoop/httpfs-signature.secret
-rw-r--r-- 3 root supergroup 620 2017-12-22 12:14 /input/hadoop/httpfs-site.xml
-rw-r--r-- 3 root supergroup 3518 2017-12-22 12:14 /input/hadoop/kms-acls.xml
-rw-r--r-- 3 root supergroup 3139 2017-12-22 12:14 /input/hadoop/kms-env.sh
-rw-r--r-- 3 root supergroup 1788 2017-12-22 12:14 /input/hadoop/kms-log4j.properties
-rw-r--r-- 3 root supergroup 5939 2017-12-22 12:14 /input/hadoop/kms-site.xml
-rw-r--r-- 3 root supergroup 14016 2017-12-22 12:14 /input/hadoop/log4j.properties
-rw-r--r-- 3 root supergroup 1076 2017-12-22 12:14 /input/hadoop/mapred-env.cmd
-rw-r--r-- 3 root supergroup 1507 2017-12-22 12:14 /input/hadoop/mapred-env.sh
-rw-r--r-- 3 root supergroup 4113 2017-12-22 12:14 /input/hadoop/mapred-queues.xml.template
-rw-r--r-- 3 root supergroup 758 2017-12-22 12:14 /input/hadoop/mapred-site.xml.template
-rw-r--r-- 3 root supergroup 10 2017-12-22 12:14 /input/hadoop/slaves
-rw-r--r-- 3 root supergroup 2316 2017-12-22 12:15 /input/hadoop/ssl-client.xml.example
-rw-r--r-- 3 root supergroup 2697 2017-12-22 12:15 /input/hadoop/ssl-server.xml.example
-rw-r--r-- 3 root supergroup 2250 2017-12-22 12:15 /input/hadoop/yarn-env.cmd
-rw-r--r-- 3 root supergroup 4876 2017-12-22 12:15 /input/hadoop/yarn-env.sh
-rw-r--r-- 3 root supergroup 690 2017-12-22 12:15 /input/hadoop/yarn-site.xml
[root@hdp-nn-1 hadoop-2.9.0]#
Now I will run a Mapreduce Job which comes with hadoop to perform wordcount
centos@hdp-nn-1 hadoop-2.9.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar grep /input/hadoop/ output1 'dfs[a-z.]+'
17/12/24 18:39:59 INFO input.FileInputFormat: Total input files to process : 29
17/12/24 18:39:59 INFO mapreduce.JobSubmitter: number of splits:29
17/12/24 18:39:59 INFO Configuration.deprecation: yarn.resourcemanager.zk-address is deprecated. Instead, use hadoop.zk.address
17/12/24 18:39:59 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
17/12/24 18:39:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514139234722_0001
17/12/24 18:40:00 INFO impl.YarnClientImpl: Submitted application application_1514139234722_0001
17/12/24 18:40:00 INFO mapreduce.Job: The url to track the job: http://hdp-rm-1.scaleon.io:8088/proxy/application_1514139234722_0001/
17/12/24 18:40:00 INFO mapreduce.Job: Running job: job_1514139234722_0001
17/12/24 18:44:32 INFO mapreduce.Job: Job job_1514139234722_0001 running in uber mode : false
17/12/24 18:44:32 INFO mapreduce.Job: map 0% reduce 0%
17/12/24 18:44:43 INFO mapreduce.Job: map 3% reduce 0%
17/12/24 18:44:45 INFO mapreduce.Job: map 7% reduce 0%
17/12/24 18:44:47 INFO mapreduce.Job: map 17% reduce 0%
17/12/24 18:44:48 INFO mapreduce.Job: map 24% reduce 0%
17/12/24 18:44:49 INFO mapreduce.Job: map 28% reduce 0%
17/12/24 18:44:50 INFO mapreduce.Job: map 34% reduce 0%
17/12/24 18:44:53 INFO mapreduce.Job: map 41% reduce 0%
17/12/24 18:44:54 INFO mapreduce.Job: map 48% reduce 0%
17/12/24 18:44:56 INFO mapreduce.Job: map 52% reduce 0%
17/12/24 18:44:57 INFO mapreduce.Job: map 59% reduce 0%
17/12/24 18:44:58 INFO mapreduce.Job: map 72% reduce 0%
17/12/24 18:44:59 INFO mapreduce.Job: map 86% reduce 0%
17/12/24 18:45:01 INFO mapreduce.Job: map 90% reduce 0%
17/12/24 18:45:02 INFO mapreduce.Job: map 97% reduce 0%
17/12/24 18:45:03 INFO mapreduce.Job: map 100% reduce 0%
17/12/24 18:45:04 INFO mapreduce.Job: map 100% reduce 100%
17/12/24 18:45:05 INFO mapreduce.Job: Job job_1514139234722_0001 completed successfully
17/12/24 18:45:05 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=817
FILE: Number of bytes written=6247136
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=94274
HDFS: Number of bytes written=999
HDFS: Number of read operations=90
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=29
Launched reduce tasks=1
Data-local map tasks=29
Total time spent by all maps in occupied slots (ms)=254649
Total time spent by all reduces in occupied slots (ms)=13547
Total time spent by all map tasks (ms)=254649
Total time spent by all reduce tasks (ms)=13547
Total vcore-milliseconds taken by all map tasks=254649
Total vcore-milliseconds taken by all reduce tasks=13547
Total megabyte-milliseconds taken by all map tasks=260760576
Total megabyte-milliseconds taken by all reduce tasks=13872128
Map-Reduce Framework
Map input records=2400
Map output records=43
Map output bytes=1121
Map output materialized bytes=985
Input split bytes=3389
Combine input records=43
Combine output records=28
Reduce input groups=26
Reduce shuffle bytes=985
Reduce input records=28
Reduce output records=26
Spilled Records=56
Shuffled Maps =29
Failed Shuffles=0
Merged Map outputs=29
GC time elapsed (ms)=9452
CPU time spent (ms)=17530
Physical memory (bytes) snapshot=8662618112
Virtual memory (bytes) snapshot=63645687808
Total committed heap usage (bytes)=6047662080
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=90885
File Output Format Counters
Bytes Written=999
17/12/24 18:45:05 INFO input.FileInputFormat: Total input files to process : 1
17/12/24 18:45:05 INFO mapreduce.JobSubmitter: number of splits:1
17/12/24 18:45:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514139234722_0002
17/12/24 18:45:05 INFO impl.YarnClientImpl: Submitted application application_1514139234722_0002
17/12/24 18:45:05 INFO mapreduce.Job: The url to track the job: http://hdp-rm-1.scaleon.io:8088/proxy/application_1514139234722_0002/
17/12/24 18:45:05 INFO mapreduce.Job: Running job: job_1514139234722_0002
17/12/24 18:45:12 INFO mapreduce.Job: Job job_1514139234722_0002 running in uber mode : false
17/12/24 18:45:12 INFO mapreduce.Job: map 0% reduce 0%
17/12/24 18:45:17 INFO mapreduce.Job: map 100% reduce 0%
17/12/24 18:45:22 INFO mapreduce.Job: map 100% reduce 100%
17/12/24 18:45:23 INFO mapreduce.Job: Job job_1514139234722_0002 completed successfully
17/12/24 18:45:23 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=763
FILE: Number of bytes written=417029
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1131
HDFS: Number of bytes written=549
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2630
Total time spent by all reduces in occupied slots (ms)=2778
Total time spent by all map tasks (ms)=2630
Total time spent by all reduce tasks (ms)=2778
Total vcore-milliseconds taken by all map tasks=2630
Total vcore-milliseconds taken by all reduce tasks=2778
Total megabyte-milliseconds taken by all map tasks=2693120
Total megabyte-milliseconds taken by all reduce tasks=2844672
Map-Reduce Framework
Map input records=26
Map output records=26
Map output bytes=705
Map output materialized bytes=763
Input split bytes=132
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=763
Reduce input records=26
Reduce output records=26
Spilled Records=52
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=154
CPU time spent (ms)=1350
Physical memory (bytes) snapshot=497348608
Virtual memory (bytes) snapshot=4251115520
Total committed heap usage (bytes)=322961408
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=999
File Output Format Counters
Bytes Written=549
[centos@hdp-nn-1 hadoop-2.9.0]$We can see above job is successfully completed . Lets verify the wordcount result
[root@hdp-nn-1 hadoop-2.9.0]# bin/hdfs dfs -cat /user/centos/output1/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
3 dfs.logger
2 dfs.audit.log.maxbackupindex
2 dfs.period
2 dfs.namenode.rpc
2 dfs.namenode.http
2 dfs.audit.log.maxfilesize
1 dfs.namenode.shared.edits.dir
1 dfsadmin
1 dfs.namenode.name.dir
1 dfsmetrics.log
1 dfs.server.namenode.ha
1 dfs.log
1 dfs.journalnode.edits.dir
1 dfs.ha.namenodes.hdpdev
1 dfs.ha.fencing.ssh.private
1 dfs.ha.fencing.methods
1 dfs.ha.automatic
1 dfs.file
1 dfs.client.failover.proxy.provider.hdpdev
1 dfs.replication
1 dfs.permissions
1 dfs.servers
1 dfs.nameservices
[root@hdp-nn-1 hadoop-2.9.0]#
Now lets verify on Yarn Web UI
I am text block. Click edit button to change this text.

We have successfully setup a Hadoop High Availability Cluster. Drop a note if you have any question. Thanks
