

Props to MLOps: Go Dev to Prod the smart way
By Vaishnavi Sonawane / May 12, 2023
If I ask you to take a guess on what percentage of Machine Learning models you think to fulfil their destiny and make it into production, what will be your answer? The answer to this question is quite shocking. Approximately just 20% Machine Learning models make it into production. In other words, 80% of Machine Learning projects never get deployed. And no, bad models aren't the reason.
Industry research by Thomas Davenport and Katie Malone's article backs up this surprisingly low success rate.
The belle of the ball in any Data Science/ML project is never just the trained model. As you can see in the below diagram, a lot of other components factor into the successful deployment of a ML model.
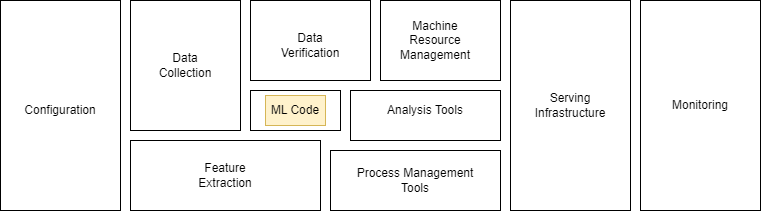
So, now the question of the hour is, how can we make sure we deploy our ML solutions efficiently, optimally and successfully?
This is where Machine Learning Operations (MLOps) come into the picture. Having the right MLOps strategy helps you orchestrate and operationalize the ML pipelines for your solutions. It focuses on the deployment of a trained ML Model.
From a high-level point of view, MLOps is more of a-- set of planned steps-- principles we can follow-- an ideal framework. It is language-, platform-, and infrastructure-agnostic. So regardless of what your specific ML use-case is, you can always rely on framing your solution around MLOps.
The diagram below represents a high-level workflow of a Machine Learning pipeline in production.
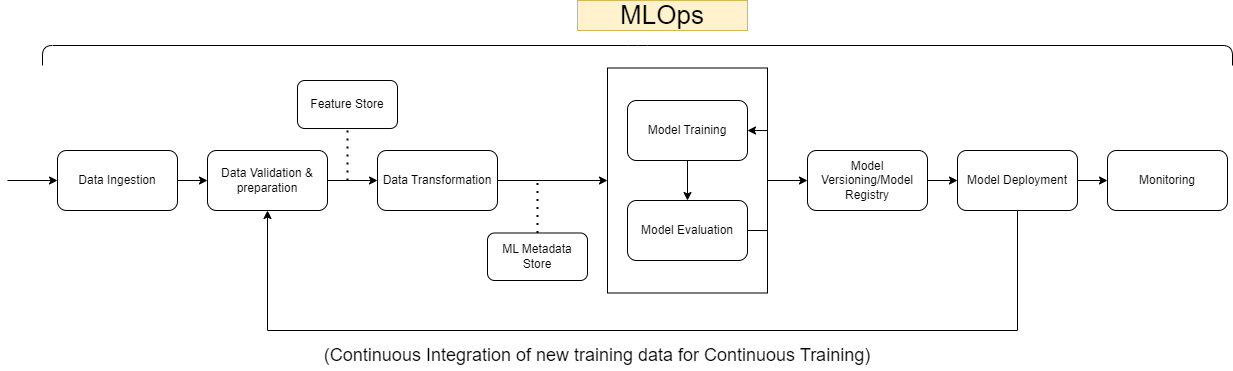
Let’s take a closer look, shall we? A MLOps workflow is generally divided into the following stages:
Data Ingestion:
Here is where we determine where our data is coming from. It could be coming in from multiple different sources. This is the stage where we ask questions like:
- What are the sources of our data? And how many?
- Are we ingesting streaming data or batch data?
- What is our ETL (Extract, Transform and Load) strategy?
- What is the format of the data?
- How large is the data?
- Where should we store it?
After determining the answers to these questions, we need to decide how we can efficiently ingest this data in a way that there is no data loss.
Data Validation & Preparation:
This stage is where Data profiling takes place. Here we obtain more information about the content and structure of the ingested data. This information is stored as metadata. The metadata contains statistical information about the ingested data. Using this metadata, we can generate a Data Schema which we can use to validate the distribution of new data for re-training.
Then, we split the data into training, testing and validation datasets.
**Feature Store:
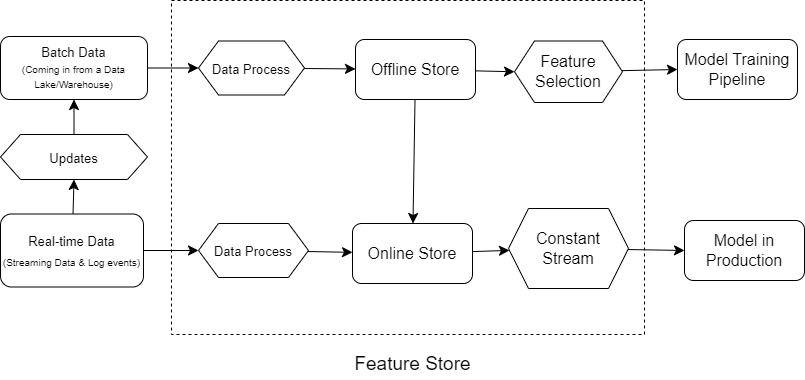
A Feature Store is something that can be created independent of a specific ML project. A Feature Store is used to process data from various data sources at the same time and turn it into features, which then are fed to the ML model for training in the pipeline.
In other words, it is used to provide online features that are relevant to a ML model in production. The above diagram provides a high-level view of a feature store.
For instance, Feast (Feature Store) is an open-source feature store which helps ML teams manage and serve features to real-time models. It is a great stand-alone feature store which we can directly integrate to our data pipelines with existing tools. It is used by a wide range of companies including gojek, IBM, Google Cloud and redis.
A real-world use case for this will be predicting if a cab driver will complete their trip using features ingested into Feast.
Data Transformation:
Here is where we preprocess the data to ensure it does not have any errors like missing values, duplicate values etc. Here, we also perform re-formatting of data attributes for creating a richer training dataset.
**ML Metadata Store:
You could be working on any kind of ML model. But, that model will definitely need data to be trained on and it has to pass through a lot of stages before making it into production.
- Experimentation
- Training
- Hyperparameter tuning
- Evaluation
- Interpretation
- Comparison of its performance to a baseline model
Every stage generates metadata with more & more information about our model. We can find all model-related metadata in ML Metadata Store. Metadata about all the experiments, artifacts, models and pipelines can be stored and managed in a ML Metadata Store. It is independent of a single project and can be used to fastrack time-to-delivery.
Model Training & Evaluation:
Here is where we finally train the ML model on the transformed training data. Post training, the ML model should be tested on the following grounds:
- Performance: It should be tested using loss metrics (like MSE, MAE, log-loss etc.) with a pre-determined threshold value. This is to ensure that the decision making done by the model is in alignment with the business objective.
- Bias: The Bias factor should be kept in mind while testing the model. The model should be tested for its “fair” decision making.
- Staleness: A ML model can be considered stale if it’s not trained on the latest data or is not up-to-date with the latest business requirements. Hence, tests should be designed to determine if a model has gone stale and required actions should be performed if it has.
- Data Drift: Data distribution tends to change over time, and it can differ from the data distribution the model was previously trained on. If the results of training the model on current data differ significantly from when you previously trained the model, it means there is data drift, and you need to update the workflow steps according to the latest data distribution.
Model Versioning:
The requirements for Data & ML training scripts can change owing to many reasons like new training data coming in, change in data schema, refactoring of the ML training techniques etc. Hence, we need to update the pipeline accordingly. Enabling versioning helps in quick roll-back to a previously deployed model if things go south during the deployment of a new one. It also helps if an audit is required by the corporate or government for compliance of the data and the model.
Model Deployment:
Here is where we ‘package’ the model to export it into a specific format like ONNX, PFA, PMML etc. to finally serve it into production.
Monitoring:
Testing of this phase is crucial. This is where we monitor the decay of the ML model. By keeping track of metrics like F1-score over regular time intervals, we can set triggers for model re-training and recover the model's health.
Overall, Machine Learning Operations is a union of the following principles:
Continuous X Principles
Continuous Integration (CI):
In MLOps, CI means continuously testing and validating code and components with test and validation data to avoid crashing the ML model and subsequent system downtime.
Continuous Delivery (CD):
Following this principle, a ML pipeline should be orchestrated such that the deployment of a new ML model will be quick and obstacle-free.
Continuous Training (CT):
This principle enables the ML system to easily integrate the new training data for re-training & re-deploying the ML model.
Continuous Monitoring (CM):
This principle concerns tracking the performance metrics of the ML model which impacts the business metrics.
Remember,
“Data is the new science. Big Data holds the answers.”
But we will never be able to put this precious data to use if we can’t deploy our ML models into production successfully. For that, MLOps is the way to go!
References:
[1] Denis Baylor, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, Mustafa Ispir, Vihan Jain, Levent Koc, Chiu Yuen Koo, Lukasz Lew, Clemens Mewald, Akshay Naresh Modi, Neoklis Polyzotis, Sukriti Ramesh, Sudip Roy, Steven Euijong Whang, Martin Wicke, Jarek Wilkiewicz, Xin Zhang, and Martin Zinkevich. 2017. TFX: A TensorFlow-Based Production-Scale Machine Learning Platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '17). Association for Computing Machinery, New York, NY, USA, 1387–1395.
[2] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F. & Dennison, D. (2015). Hidden Technical Debt in Machine Learning Systems. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama & R. Garnett (eds.), NIPS (p./pp. 2503-2511).
[3] Arthur Quintella de Mello Olga. (2021, April 7). Feature Storing. MLOPs Guide. https://mlops-guide.github.io/MLOps/FeatureStore/
