
AI Hardware accelerators
By Vaishnavi Sonawane / Feb 01, 2024
Table of Contents
- If I were to ask you to identify the factors behind the success of AI today, what would they be?
- The story
- AI Hardware Accelerators
- Never been a better time to invest
- What are MLPerf benchmarks?
- Conclusion
- References
If I were to ask you to identify the factors behind the success of AI today, what would they be?
Based on my observation, there are 3 main factors -
- Research Initiatives that drive innovative algorithms
- Centralized architectures that enable collecting, organizing & analyzing large amounts of data
- Cutting-edge computing infrastructure capable of processing large amounts of data at massive scales
Let’s zoom in on the third factor – Compute Infrastructure
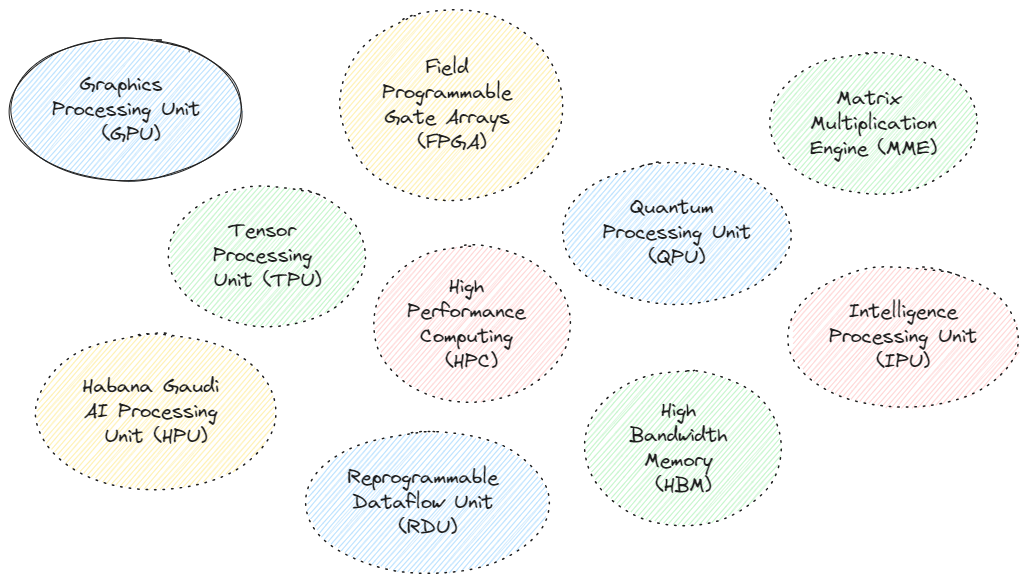
Above is a list of AI Hardware accelerators. Quite a list, right? Do not worry. Let’s start with a little story. Trust me, knowing this story will help you build a perspective.
The story
Do you know who is the Father of Deep Learning?
So, in 1957, Frank Rosenblatt published his work on the very first machine learning algorithm for artificial neurons [1]. These neurons were and still are famously known as the perceptron.
Considering how deep learning has enabled us to make AI write, talk, sing, generate art & videos and what not today, all this actually dates back to contribution from Rosenblatt and other visionaries from the late 1950s.
So, if Deep Learning has existed for around 60 years, why did its applications have gotten popular just around the past decade?
The (Re)Discovery of Deep Learning started around 2012 with a paper proposing a deep neural network known as “AlexNet” [3]. AlexNet was developed by Ilya Sutskever, Alex Krizhevsky and Geoffrey Hinton, a research team from the University of Toronto.
AlexNet won the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) where, as the name of the challenge suggests, the goal was to perform object recognition on ImageNet (a very large dataset).
This was a pivotal moment in AI history as this was the very first time someone had used Deep Convolutional Neural Networks (DCNNs) to win this challenge.
But, CNNs already existed since the introduction of LeNet [2] in 1995.
Then why was AlexNet a huge success? What did they do different?
The secret sauce? The authors of AlexNet invested considerable effort in mapping the time-consuming convolutional operations to a GPU (graphics processing unit). GPUs, initially specialized in computer graphics and linear algebra-based computations (which are abundant in CNNs), offered faster performance compared to standard processors. The efficient implementation on GPUs contributed to a reduction in the overall time required for training the network. Additionally, the authors provided insights into the mapping of their network onto multiple GPUs, enabling the deployment of a more extensive and deeper network for faster training.
The team used two NVIDIA GTX 580s each with 3GB of memory, either of which was capable of 1.5 TFLOPs (a metrics to calculate no. of arithmetic operations in deep learning architectures, this many TFLOPs is still a challenge for most CPUs today a decade later) to implement faster convolutions. This cuda-convnet code was the industry standard for several years and helped power the first couple of years of the deep learning boom.
Moral of the story.
Algorithmic progress in AI is of course important. But it was the use of specialized GPU hardware that enabled us to learn more complex patterns (with larger data) at reasonable times. Without these computing capabilities to process the data within a reasonable about of time, the widespread adoption of deep learning applications would not have been possible.
This story very well represents the significance of hardware accelerators for machine learning training & inference.
AI Hardware Accelerators
At the beginning there were just GPUs. But now there are also TPUs, IPUs, FPGAs, HPUs, QPUs, RDUs and more are being invented (full-forms in the list at the top).
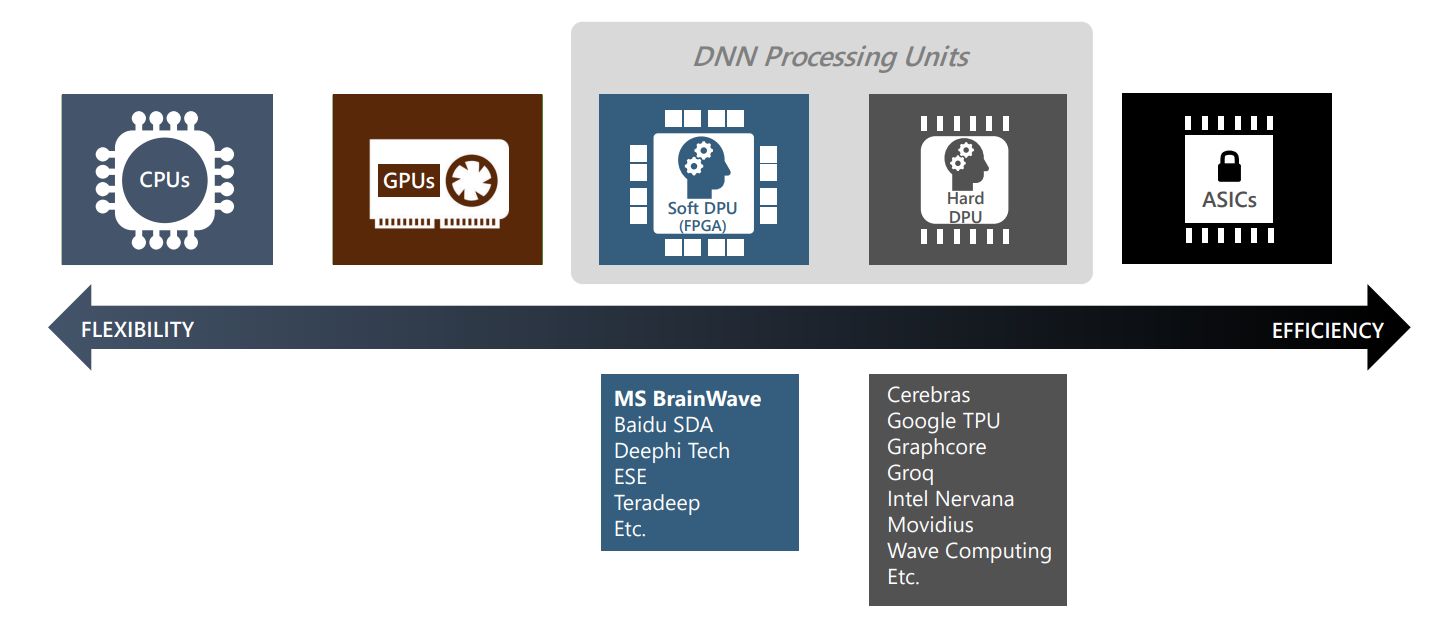
Let’s take this slide from this deck for an instance.
CPU
You move to the left, you will find hardware that will lean towards general purpose programming more (For context, our CPUs are based on general purpose programming). Record audio, process video, run code... it will do all. But energy and performance efficiency will be compromised.
GPU
Moving to the right, we have GPUs. GPUs are special purpose processors unlike CPUs. They excel at parallel workloads like graphics sharded computations and matrix multiplications. CPUs are better suited for applications sensitive to latency, whereas GPUs are a better fit for applications that need high throughput. GPUs are programmable. They work with languages like NVIDIA CUDA, AMD HIP and OpenCL. They really excel at code that exploits parallelism.
FPGA
You move towards the middle, you will find Field-programmable gate array (FPGA). These chips enable you to reprogram logic gates. Basically, you can use FPGA technology to overwrite chip configurations and create customized circuits. FPGA chips are especially useful for machine learning and deep learning. For example, using FPGA for deep learning enables you to optimize throughput and adapt processors to meet the specific needs of different deep learning architectures. Neat, right?
DPU
Closer to the ASICs is the Deep Learning Processor Unit (DPU) which is a programmable engine dedicated to convolutional neural network. There is a specialized instruction set for DPU, which enables DPU to work efficiently for many convolutional neural networks.
ASICs
On the other end of the spectrum are Application Specific Integrated Circuits (ASICs). These are also called fixed function silicon. This is so because they exist to do just one or few specific things and are not normally programmable and do not expose developer focused APIs.
Never been a better time to invest
Valuation of AI Hardware Market Size and trend
The global artificial intelligence in hardware market size was valued at USD 43.06 billion in 2022 and it is projected to surpass around USD 248.09 billion by 2030 and grow at a compound annual growth rate (CAGR) of 24.5% from 2023 to 2030.
This report includes a comprehensive overview zooming in on various segments as depicted in the snippet below.
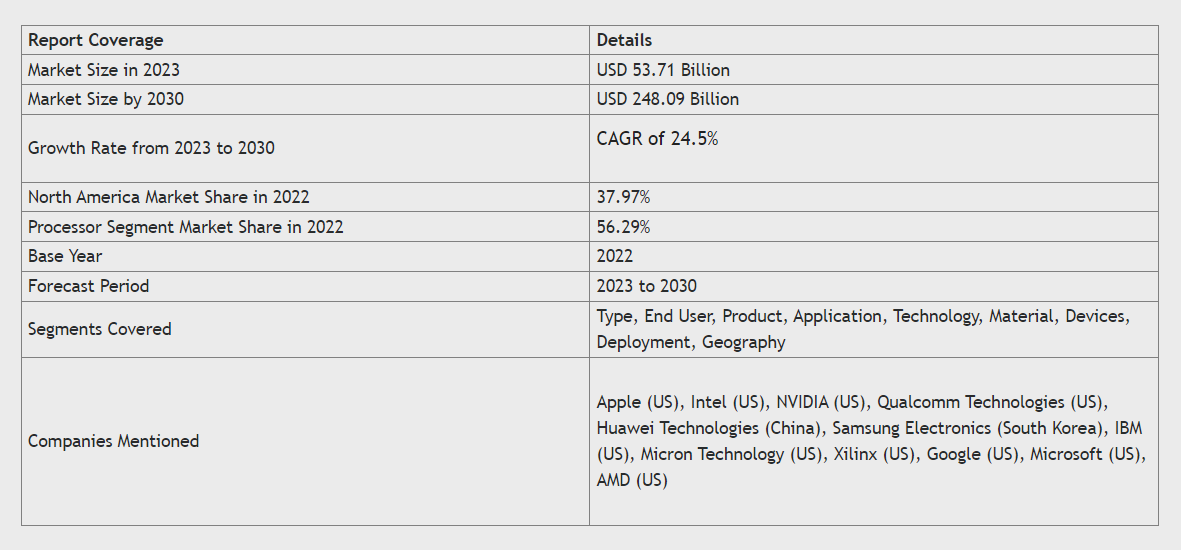
Now that the numbers have got our attention-
Let's zoom in on how other companies have been growing in the landscape.
Commoditization is a driving force behind the greatest technological revolutions, and Generative AI is no different.
The most important factor for successful commoditization is solid (and very expensive) infrastructure. The current scale of Generative AI services requires a large amount of compute power to provide high availability. Let’s dare to assume that two or three years ago, OpenAI did not possess the infrastructure at a capacity that would withstand the computational costs of a service like ChatGPT, or at least it could not have provided the same quality of service. Imagine if ChatGPT would have taken, let’s say, 30 minutes to answer each prompt. It would probably not have been nearly as successful.
The ability to scale large compute and easily ship it is a key driver for commoditization. Lot of money has been spent and compute infrastructure demands will only rise.
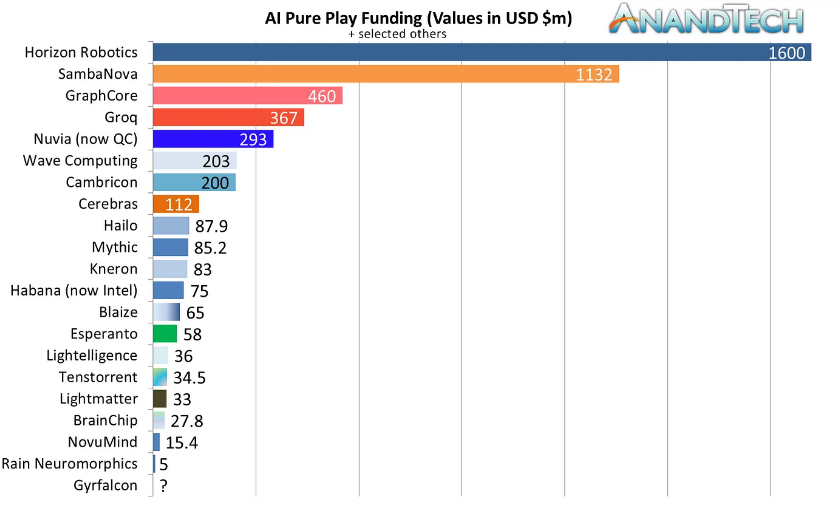
The recent years have been the golden age for many AI hardware accelerator companies. For an instance, NVIDIA’s stock has skyrocketed by about +500% in the past three years! Thus, dethroning Intel as the world’s most valuable chip company. The startup scene also seems to be just as hot; billions of dollars have been spent in funding AI hardware startups.
NVIDIA
NVIDIA charges the AI battlefield from two angles:
- Strengthening its line of GPUs with new architectural innovations like Tensor Cores and strong collaboration with the research community to assert its market dominance
- Taking full control of the system stack, with multi-billion dollar acquisition like Mellanox to attain smart networking processing capabilities in the form of DPUs (Data Processing Units), and the following acquisition of ARM which sells CPU cores and IP rights that are a part of manufacturing of billions of phones and mobile devices around the world
CEREBRAS
Another interesting company in the landscape is Cerebras. It was founded in 2016. Targeting the demand for compute to tackle bigger and more complex AI models, they designed a Wafer-Scale Engine (WSE) which is a “chip” the size of a Pizza box.
For context, typical processing chips are fabricated on a piece of silicon called a “wafer.” The wafer is dissected into smaller pieces called “dies” during the manufacturing process to make a processing chip. Usually, a typical wafer holds hundreds or even thousands of such chips, with each chip size typically ranging between 10 mm² and up to around 830 mm² (the manufacturing limit for a single die). NVIDIA’s A100 GPUs are considered almost the biggest processing chip possible at 826 mm² which allows them to pack 54.2 billion transistors powering around 7000 processing cores.
Cerebras does not only plan to enable supercomputer capabilities on a single large chip, they also provide a software stack and compiler toolchain via collaborations with academic institutes and US national labs. Their software framework is based on a Linear-Algebra Intermediate Representation (LAIR) and a c++ extension library that can either be used by low-level programmers to write manual kernels (which is similar to NVIDIA’s CUDA) or can be used to seamlessly lower high-level python code from frameworks like PyTorch or TensorFlow.
Cerebras’ unconventional approach is intriguing as it takes on a very daring challenge that multi-billion dollar corporations will hesitate to take, let alone a startup like theirs!
GRAPHCORE
GraphCore is one of the leaders in presenting a commercial AI accelerator called the “Intelligent Processing Unit” (IPU). They announced several collaborations with Microsoft, Dell, and other commercial and academic institutes. Their solution is based on an in-house software stack called “Poplar”. Poplar enables lowering Pytorch, Tensorflow, or ONNX-based models to an imperative, C++ compatible code, in favor of what the company termed as: “vertex programming”. Similar to NVIDIA’s CUDA, Poplar also supports low-level C++ programming of kernels to achieve better potential performance (compared to python applications that were lowered via the Poplar compiler.)
SAMBANOVA
SambaNova is another company that has gained a lot of traction with multiple announcements of the biggest-ever funding series in the landscape. It was founded in 2017.
SambaNova is targeting AI inference and training and thus building chips, racks, and software stacks for datacenters. Its architecture is based on reconfigurable dataflow unit (RDU). The RDU chip contains an array of compute units called PCUs and scratchpad memory units called PMUs organized in a 2D-mesh hierarchy interconnected with network-on-chip (NoC) switches the RDU accesses off-chip memory using a hierarchy of units called AGUs and CUs.
SambaNova has showcased how the RDU architecture runs complex NLP models, recommender models, and high-resolution vision models. SambaNova’s software stack called Sambaflow takes high-level python applications (e.g. in PyTorch, TensorFlow) and lowers them into a representation that can program the chip’s switches, PCUs, PMUs, AGUs, and CUs at compile-time, with the dataflow inferred from the original application’s computation graph.
Google’s Tensor Processing Unit (TPU) was one of the world’s first processors tailored specifically for AI. TPU was presented in 2017 as a programmable Application-Specific Integrated Circuit (ASIC) for Deep Neural Networks (DNNs). Meaning, it was a chip designed and fabricated from the ground up for a specific task or a set of tasks. Google scientists did a study internally in which they concluded that the rise in computing demands of Google Voice search alone would soon require them to double their datacenter if they were to rely on traditional CPUs and GPUs. In 2015, therefore, they started working on their own accelerator chip designed to target their internal DNN workloads such as speech and text recognition.
The first-generation TPU was built for inference-only workloads in Google’s datacenters, and combined a systolic array called a Matrix-Multiply Unit”\ and a VLIW architecture. In the following generations, Google’s engineers designed the TPUv2 and TPUv3 to do AI training. They used larger matrix multiply units and added new tensor units like the transpose-permute unit. They used liquid cooling and a purpose-built torus-based interconnection architecture that scales to thousands of accelerators which form an AI training supercomputer.
Habana
Habana also has an interesting approach and story. It was founded back in early 2016 as an AI accelerator company targeting training and inference in datacenters. In contrast to most startups in the AI data center landscape, Habana presented an open approach to its chip offerings and their performance. In about three years they showcased two chips for different applications: Goya for inference and Gaudi for training.
Given that usually it would take you at least two years from the initial planning to have a new chip working, and that is when you already have a team and not building one in your new startup (and that you’re lucky enough to have a successful tape-out), they operated at very ambitious timelines.
While other startups concentrated on catering to individual customers and addressing their private models, Habana distinguished itself by actively participating in MLPerf (see the section below), an industry-wide initiative that aims to establish a standardized benchmark suite for AI processors. In November 2019, Habana boldly shared its Goya inference performance results, directly competing with major players such as NVIDIA and Google, and notably outperforming Intel's Datacenter inference processor, NNP-I. A mere month after the publication of these MLPerf results, Intel made a significant move by acquiring Habana for a substantial 2 billion dollars. This acquisition signaled Intel's intention to replace existing solutions, highlighting the success of Habana's strategic focus on MLPerf.
NeuReality, Mythic, TensTorrent, Esperanto are some of the other companies doing good in this space.
There has never been a better time to understand and potentially invest in this domain.
What are MLPerf benchmarks?
For all the companies discussed above, an essential aspect of developing and sustaining new products involves objectively measuring the performance of machine learning (ML) tools. Without a clear understanding of how current solutions compare to alternative possibilities, it's challenging to ensure that the chosen approaches are optimal.
The AI industry too is now seeking standardized protocols to drive advancements in machine learning operations. MLPerf's primary purpose is to provide a standardized method for assessing workloads, bringing together over 40 organizations to collaboratively define a consistent set of benchmarks for evaluating ML workflows.
If you are a business leader/decision-maker, these benchmarks will help you establish your foundational goals. If you are an engineer, it will help you understand how your choices affect the efficiency & performance of your workloads (monetarily & otherwise).
Conclusion
My intention behind this blog was to help you build a 360 degree perspective when it comes to -
- Addressing that while algorithmic progress is important in AI, commoditization of AI (Generative & otherwise) would not have been possible without AI hardware accelerators
- Discuss the varied range of AI hardware accelerators available today
- Provide an overview of the booming AI Hardware Market & the companies who are doing well
- Provide an overview of MLPerf Benchmarks, why they are important and if you decide to invest in/start your own startup, what should you look out for 😉
References
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65, 386--408.
- LeCun, Y., Bengio, Y., & et al. (1995). Convolutional networks for images, speech, and time series. The Handbook of Brain Theory and Neural Networks (p. 3361). MIT Press.
- Krizhevsky, A., Sutskever, I. & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. In F. Pereira, C. J. C. Burges, L. Bottou & K. Q. Weinberger (ed.), Advances in Neural Information Processing Systems 25 (pp. 1097--1105) . Curran Associates, Inc..
- AI Accelerators Blog Series
- AI in Hardware Market Report 2023
- AI Funding Spree: +$300m for Groq, +$676m for SambaNova
