
VMware vRNI Architecture Explained
By Bharath Babbur / Oct 11,2021
VMware vRealize Network Insight popularly knows a vRNI (a.k.a varni) is a very powerful tool that provides intelligent services for software-defined networking environments (especially NSX). It provides management for virtualized networks (only for SDN networks). Based on visualization and analysis capabilities of physical and virtual networks provided by VMware vRNI, VMware vRNI can optimize the network performance to achieve the best service deployment effect.
The vRNI has 2 main components that make up the deployment:
- The Platform Appliance
- The Proxy \ Collector VM
The Platform VM:
The Platform VM has 3 main parts which work in tandem to perform analytics, provides search abilities and the UI.

UI, REST API, search engine
- UI on top of REST API (private)
- Search engine –SDDC models awareness –Combines configuration, flows, performance data
- Flow analytics components (high performance) –Access flows at large scale –Analyze flows, rules, micro-segmentation graphs
Storage and search engine
- Stores configurations, changes, performance stats
- Indexes configurations, events
- Supports data retention policy
Analytics grid
- Store data from proxy VMs
- Processes in real time, batch
- VXLANs graphs, paths, MTU events
The Proxy \ Collector VM:
The Proxy VM multiple components like Offline Message Store, Flow processor, proxy service, postgres DB
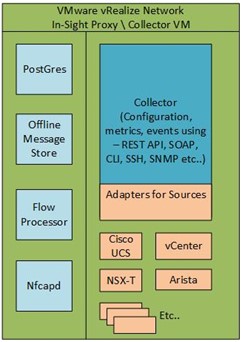
Proxy
Collects data from data sources using appropriate protocol(s). Receives IPFIX (NetFlow) data from ESX on port UDP:2055 Securely pairs with platform before uploading data or getting instructions Reduces / batches data significantly before upload
Offline message store
Proxy can store up to 3 days of data after disconnecting from platform Restricted to 15GB of disk space Good for few hours to days of data depending on size of environment
Flow processor (high performance)
Processes raw flow records files (nfcapd), generates 5-tuples, 4-tuples, and aggregate statistics Apply algorithms, heuristics to stitch records, dedups, avoid negative scenarios (port scan, …)
Collector process
Only way to upload data, receive instructions from platform Platform not available then Store in offline message store Has specific adapters for data sources, get data messages from them Receives data from Flow Processor Adapters may use Postgres to keep some state
In this section Let us Focus on the vRNI working with NSX-T to aid network monitoring for this blog.
First of all, what is a Flow?
In simple terms, a network flow is a series of communications between two endpoints. Beyond these characteristics, however, the definition of a flow may not be totally clear for everyone. When utilized in the context of NetFlow or IPFIX records, most people can agree that we typically define a flow by its 5-tuple attributes (source and destination IP, source and destination port and the protocol field). But it is also common to use either a 4-tuple, dropping the protocol field, or even a 2-tuple, using only the IP addresses. The latter has the advantage that it does work for IP fragments as well.
Simply, packets make a session and sessions make a flow
Let us first understand how the Flows to generate flows from vDS and NVDS and how it is collected by vRNI For vDS:
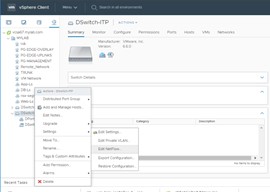
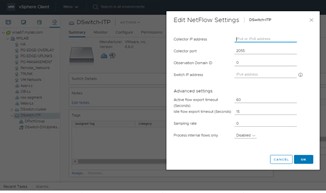
First, we need to enable the Netflow on the vDS to send it to vRNI proxy \ Collector VM
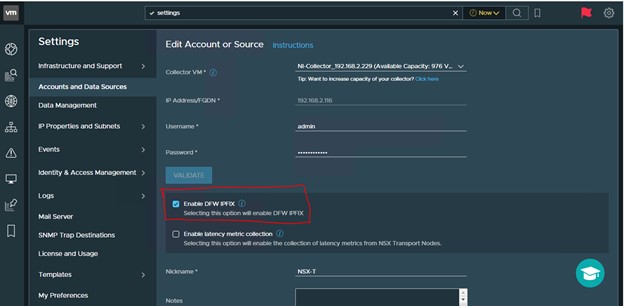
For NVDS:
The steps as for NvDS is to enable DFW IPFIX from vRNI, because Switch IPFIX is not supported
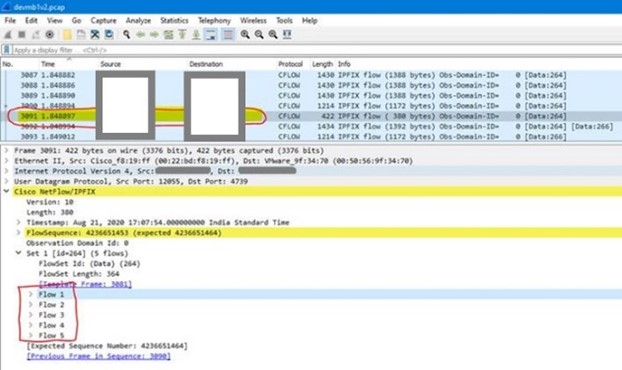
Now lets see how vRNI processes Flows from both vDS and NVDS
| vDS | NVDS |
| Generates a 5 Tuple Flow | Generates 5 Tuple Flow |
| vRNI Drops the Source port bit and converts the flow into 4 Tuple | There is no bit array drop that occurs or flow cumulation |
| vRNI then cumulates all the flows captured with similar bit arrays into one flow so effectively if 2 VMs are talking to each other the whole day, its just one flow | Unlike in vDS there is only one flow generated at source for each communication. NVDS does not capture different TCP Flags as different Flows |
| The vRNI uses the “SYN” and “ACK” flag data to identify which is the server and client in that communication, so we will see multiple flows in a single packet capture | There is a unique identifier which specified the server and client for the communication, so vRNI is not dependent on TCP Flags for that information, so Flows generated are less at source |
| Support Netflow v9 CFLOW records based on Cisco standard defined under : https://www.ietf.org/rfc/rfc3954.txt | Support and primarily works with Netflow v10 IPFIX, and standards defined under : https://www.iana.org/assignments/ipfix/ipfix.xhtml |
 |
 |
Different Architecture that vRNI can be deployed in:
FAQs on data retention in vRNI:
Ref link: https://docs.vmware.com/en/VMware-vRealize-Network-Insight/5.3/com.vrni.faq.doc/GUID-BEE1D7C4-052C-46D3-8E11-4A15030C5E8E.html
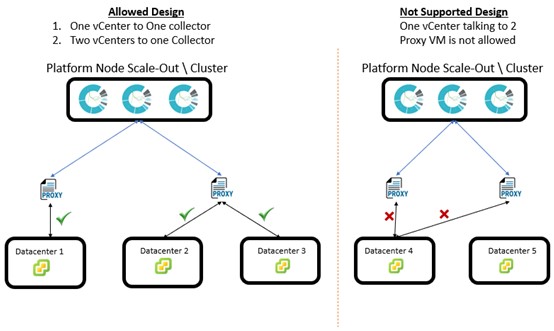
Key things about platform VM to keep in Mind while designing a vRNI:
- The Platform Nodes are not a HA Cluster, i.e the Primary node is the Key, if the primary Node goes down, the vRNI is no longer available till it is restored.
- The Primary Node manages the Load and distributes the work to other Platform nodes in the cluster
- vRNI platform VM’s sitting Load Balancer is not a supported design unfortunately.
FAQs on data retention in vRNI:
Ref link: https://docs.vmware.com/en/VMware-vRealize-Network-Insight/5.3/com.vrni.faq.doc/GUID-BEE1D7C4-052C-46D3-8E11-4A15030C5E8E.html
- What is the default retention period?
A. 30 days. It can be increased from UI with Enterprise License. Note: When increasing make sure to follow disk guidelines. - How data is handled on Proxy?
A. All data on proxy is converted to SDM (Self Describing Message) before sending it to platform including flow data. It includes all config, inventory and metric data from any data source. If platform is not reachable or SDM upload to Kafka queue fails then they are written on disk on proxy vm (under /var/BLOB_STORE). - When will data start to purge on Proxy?
A. For non-flow data: There is 10GB space allocated to store SDMs on disk (BLOB_STORE). When this store fills, collector starts deleting older SDMs and adds new SDMs to the disk. It depends on the size of data gathered from all data sources how quickly this limit is breached.
For flow data: There is 15 GB space allocated to store raw flows (under /var/flows/vds/nfcapd). As soon as this space is consumed flow processor starts deleting older flow files. At incoming raw flows rate of ~2M/min it would take ~10hrs till rotation start to occur. - What is the purge logic?
A. Oldest SDMs get deleted first. - When will new data stop being processed in Proxy?
A. Never, as long as services are running properly. - Assuming disconnect between Platform and Proxy and No purge condition met, would all data be reconciled on Platform on re-connect?
A. All data stored on disk will be sent to platform. It should be reconciled completely except if data loss conditions exist on platform (more info below). - What are the conditions when data loss can occur on Platform?
A. Platform starts to drop SDMs that are on Kafka queue for more than 6hrs (18hrs if it is a 3-node cluster). Another possibility is if the queue is saturated. It can happen when there is Lag built up in system and incoming data rate is high. - Will latest SDM be published first or earliest one in that order?
A. Oldest SDMs are sent first. There is one known issue until v3.9 which will result in some data loss. Contact GSS for more information. - Is data stored on disk in Proxy and then pushed to Platform when there is no communication problem?
A. If there is no communication issue, then SDMs are not stored on disk. It is sent to platform from memory itself. Whenever proxy receives that there was a problem in sending SDM then only it is stored on disk. - In event of any issue how proxy learn which was last processed flow file?
A. Flow-processor maintains bookmark in DB on which was last processed nfcapd file. - What is the max size of SDM that can be processed without any issue? How can user learn about this breach?
A. There is 15MB limit on SDM size. Starting v3.9 an event is raised whenever platform drops large SDM.
How to Back-up the vRNI in your enterprise design:
Simple Answer is “Any VM based & VMware ready backup solution can be used” Ref link: https://kb.vmware.com/s/article/55829
