

Autonomous employee onboarding chatbot for a large enterprise
By Bhuvaneswari Subramani / Mar 28, 2024
Table of Contents
- Introduction
- Abstract
- Problem Statement
- Challenges
- Solution Overview
- Technical Architecture
- Results and Benefits
- Conclusion
Introduction
Do you manage a large volume of data across systems such as RDS, DB2, S3, GitHub, Confluence, Alfresco, and others?
Are you seeking GenAI applications that can limit responses to your company data, minimizing model hallucinations?
Do you need a solution to filter responses based on end-user content access permissions?
Are you keen on maintaining the accuracy and relevance of responses in conversational experiences?
Do you want to remove the undifferentiated heavy lifting of having humans respond to the end users' questions that are already available in your varied corporate document repositories?
Do you want to increase your customer/employee satisfaction manifold with efficient, automated, and accurate guidance?
If you're looking for a comprehensive cloud solution to address the aforementioned challenges, then this use case is for you. Yes, let’s go on to build autonomous employee onboarding for a large enterprise. This use case offers a comprehensive GenAI solution to address data management, user experience, access control, efficiency, and satisfaction challenges, making it ideal for organizations looking to improve their employee onboarding process.
Abstract
Generative AI is revolutionizing language-based tasks across industries and roles, creating new revenue streams, boosting productivity, and cutting costs. This use case delves into a Lex chatbot utilizing Retrieval Augmented Generation (RAG) technology. The goal is to simplify complex document searches using Amazon Kendra and Amazon Bedrock via the Langchain API through the Lambda function and the Amazon Lex chatbot integrated with the intranet. Authentication is handled using a Security Assertion Markup Language (SAML) 2.0-based identity provider (IdP) to meet enterprise identity management standards.
Problem Statement
A large enterprise with close to 70 thousand employees faces the challenge of efficiently onboarding new employees due to the vast volume of information spread across various tools like Confluence, Jira, Intranet, Slack, and others. This scattered information makes it difficult for new hires to navigate and access the necessary resources for their orientation process and impacts their efficiency, productivity and job satisfaction.
Challenges
- Data Management Dilemma
Managing large volumes of data for an enterprise, spanned across multiple systems like RDS, DB2, S3, GitHub, Confluence, Alfresco can be more challenging. In addition to that making the data easily accessible to the employees in a low code or even using natural language queries has been close to impossible so far. - GenAI Application Needs
Organizations are increasingly seeking GenAI applications that can effectively limit responses to their proprietary data. This limitation is crucial for reducing model hallucinations and ensuring accurate and relevant responses. - Content Filtering, Compliance and Accuracy
Organizations face the challenge of restricting search to company data, filtering based on user permissions, complying with data protection regulations, and ensuring the accuracy and relevance of responses in conversational experiences. Finding a solution to these challenges is crucial for maintaining data security and providing meaningful interactions.
Solution Overview
As a first step towards developing the GenAI-based solution for our problem statement, let's simplify and name it "OnboardAI chatbot".
The solution utilizes Amazon Cognito for authentication against the enterprise ADFS and AWS Lambda function to coordinate between Amazon Bedrock, Amazon Kendra, and Amazon Lex. Amazon Bedrock, coupled with the Amazon Titan model (which can be swapped with any other Amazon Bedrock model), offers Generative AI capabilities. Amazon Kendra is employed to search through a collection of documents, enabling the solution to locate relevant context for user queries. Lastly, Amazon Lex provides a conversational interface to the user, including the retention of past user questions, which is crucial for handling follow-up questions.
Here are the key components of OnboardAI at a high level.
- Amazon Bedrock: Amazon Bedrock provides a secure and scalable foundation for building applications/chatbots. Amazon Bedrock provides access to leading models including AI21 Labs' Jurassic, Anthropic's Claude, Cohere's Command and Embed, Meta's Llama 2, and Stability AI's Stable Diffusion, as well as Amazon Titan models. With Amazon Bedrock, you can select the FM that is best suited for your use case. To maximize the benefit and minimize the cost, you can adopt the serverless architecture from Amazon Bedrock, which helps to make a single API to call the supported LLMs, and have a managed service to streamline the developer workflow.
- Amazon Kendra: Amazon Kendra is an intelligent search service that can be used to enhance the search functionality of the onboarding web application. It uses machine learning algorithms to understand natural language queries and retrieve the most relevant information from disparate data sources. This can help new hires quickly find the information they need for their onboarding process. Kendra continuously improves over time by fine-tuning its machine-learning models periodically and Kendra is pre-trained with 14 industry domains.
- Amazon Lex: Amazon Lex is a service for building conversational interfaces into any application using voice and text. Embed Lex bot onto intranet website UI, which can serve as the best interface for new hires to access onboarding information.
- AWS IAM: AWS Identity and Access Management (IAM) is utilized in the use case to manage access permissions and security for the various services and resources involved:
- Control access to the Amazon Kendra index, ensuring that only authorized entities can search and retrieve data from the index.
- Manage access to the Amazon Lex chatbot, defining who can interact with the bot and what actions they can perform.
- Control access to the Amazon Bedrock service, allowing only authorized users to manage and interact with the Generative AI models.
IAM policies are created and attached to IAM roles or users, specifying the permissions they have for each service. This ensures that access is restricted based on the principle of least privilege, enhancing security and compliance.
- Amazon CloudWatch: Amazon CloudWatch is used to monitor the performance and health of the Bedrock-Kendra-Lex architecture by providing metrics, logs, and alarms for each service, enabling them to identify and resolve issues proactively:
- CloudWatch monitors Kendra's performance metrics, such as query latency, indexing rates, and resource utilization. It provides insights into Kendra's operational health and helps detect any issues or anomalies.
- CloudWatch monitors the performance of Bedrock's underlying infrastructure, such as Lambda functions, API Gateway, and other resources. It provides metrics on execution times, error rates, and resource usage, helping to optimize the performance of Bedrock.
- CloudWatch monitors Lex's performance metrics, including the number of requests, fulfilment latency, and error rates. It helps ensure that the chatbot is responding efficiently and effectively to user queries.
Technical Architecture
The technical architecture of OnboardAI
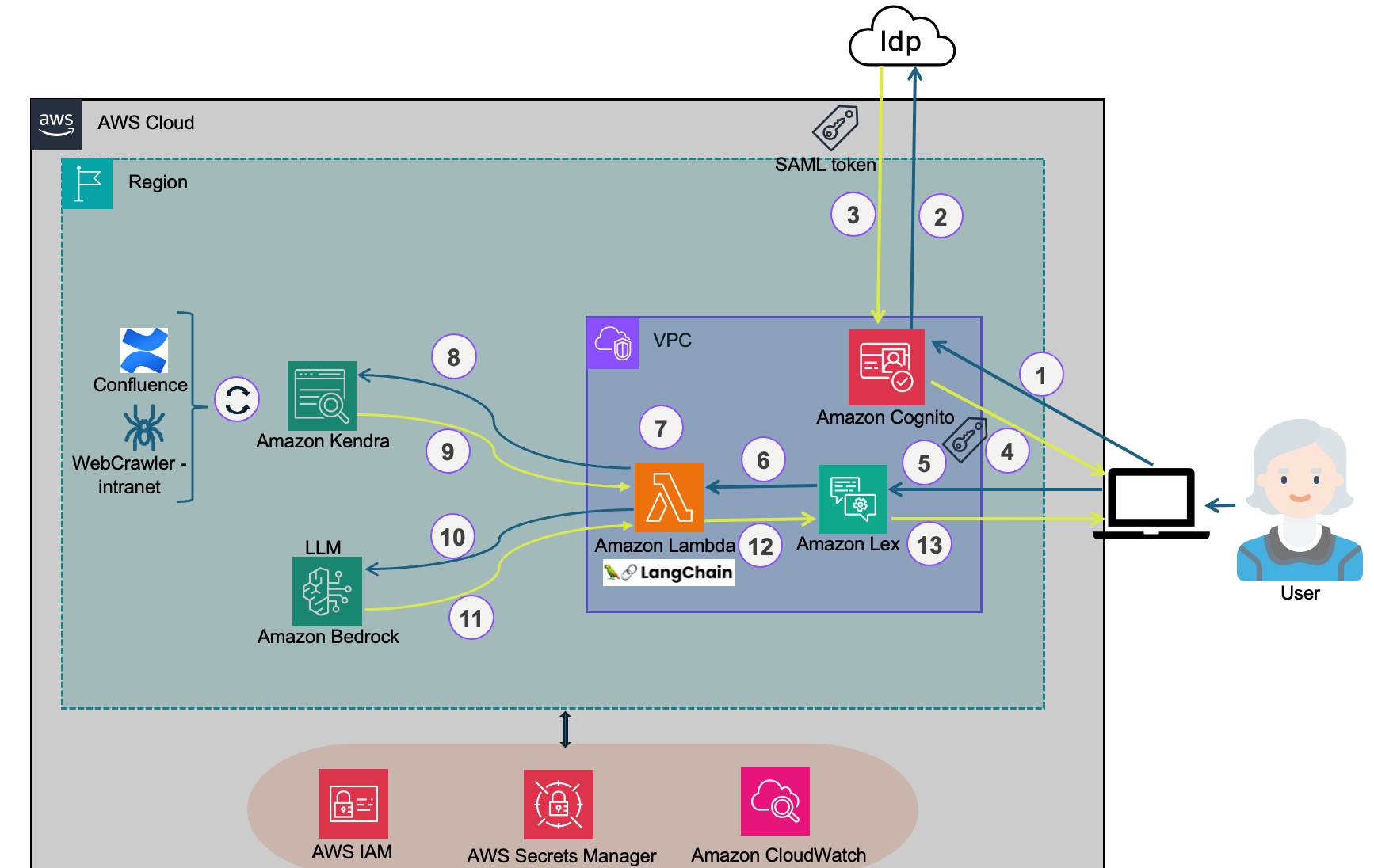
Fig 1: High-level architecture of OnboardAI
As shown in Fig 1, the high-level architecture of an autonomous employee onboarding chatbot with federated authentication typically involves the following steps:
- The employee opens the OnboardAI chatbot (Lex bot) from the intranet web UI. To add an Amazon Lex chatbot to your website, you can use an open-source project called the Lex-Web-UI
- The employee is directed to the federated IdP for login. Upon successful authentication, the IdP sends a SAML assertion or token containing the employee’s identity details to an Amazon Cognito user pool.
- Amazon Cognito user pool issues a set of tokens to the OnboardAI chatbot.
- The OnboardAI chatbot can utilize the token issued by the Amazon Cognito user pool for authorized access.
- The employee inputs a search query in natural language to the OnboardAI chatbot and sends the request.
- If OnboardAI chatbot (Lex) has the intent to address the question then Lex will handle the response.
- If Lex can't handle the question then it will be sent to the Lambda function.
- The Lambda function leverages the ConversationalRetrievalChain (langchain API) to call the Bedrock endpoint to formulate a prompt based on the question and conversation history.
- The Lambda function sends that prompt to the Kendra retrieve API.
- Amazon Kendra returns a set of context passages.
- The Lambda function sends the prompt along with the context to the Bedrock endpoint to generate a response.
- Bedrock returns the generated response to the Lambda.
- The Lambda sends the response along with message history back to the user via Lex.
- Lex retains the message history in a session and responds to the user
Around the architecture
- Periodically data from diverse data sources (say Atlassian confluence and intranet in our architectural diagram) gets synced to Amazon Kendra and indexed.
- Leverage token-based user access control in Amazon Kendra with Open ID and use Amazon Cognito user pools to authenticate users and provide Open ID tokens.
- AWS Identity and Access Management (IAM) is utilized in the Bedrock-Kendra-Lex architecture to manage access permissions and security for the various services and resources involved
- Amazon CloudWatch is used to monitor the performance and health of the Bedrock-Kendra-Lex architecture by providing metrics, logs, and alarms for each service, enabling them to identify and resolve issues proactively
Results and Benefits
Technical Transformation
- Enhanced Search Functionality: One and above the chatbot interface, AWS Kendra's intelligent search capabilities improve the discoverability of information, allowing new hires to quickly find relevant resources.
- Access-based Content Filtration: Amazon Kendra ensures a secure search for enterprise applications by only including documents in search results that the user is authorized to read. It simplifies and secures access-based filtered searches by validating the identity of users or user groups with secure search tokens.
- Data Security and Compliance: AWS Bedrock ensures data security and compliance with industry regulations, providing peace of mind for the enterprise.
Organizational Benefits
- Improved Onboarding Experience: New hires will have a more streamlined and efficient onboarding process, leading to faster integration into the company and increased productivity.
- Centralized Information: By aggregating information from various sources into a single platform, the enterprise can provide new hires with easy access to all the resources they need for onboarding.
- Reduced Time and Effort: With a more efficient onboarding process, the enterprise can save time and resources previously spent on manual onboarding tasks.
- Scalability and Flexibility: AWS Bedrock provides a scalable and flexible infrastructure, allowing the onboarding platform to grow and adapt to the needs of the enterprise.
- Improved Employee Engagement: A smoother onboarding experience can lead to higher employee satisfaction and engagement, which can positively impact retention rates.
Conclusion
Over the years, AI ML has taken tremendous strides to showcase its technological prowess and commitment to the benefit of individuals, society, and enterprises. Leveraging GenAI applications for secure access-based content searching from diverse sources can significantly enhance the onboarding experience for new employees. By ensuring that users can only access authorized information, this chatbot streamlines the process, improves efficiency, and maintains security standards. This approach not only benefits the organization but also sets a strong foundation for a seamless and productive onboarding journey for new hires.
